2. 파이썬 크롤링 - BeautifylSoup 기본기 다루기 - 1
지난번엔 크롤링을 한번 배워보기 위해 크롤링에 필요한 파이썬 라이브러리인 BeautifulSoup 라이브러리를 설치해봤어요
https://uno-kim.tistory.com/410
1. 파이썬 크롤링 - BeautifylSoup 라이브러리, 예외처리
BeautifulSoup 라이브러리파이썬에서 크롤링을 학습하기위해 간단하면서 가장 기초가되는 기능들을 사용할 수 있게해주는 라이브러리라고 생각합니다.BeautifulSoup은 HTML, XML 파일에서 데이터를 쉽게
uno-kim.tistory.com
예외처리와 라이브러리설치등을 진행했는데 이제 어떤 속성들을 이용해서 HTML을
분석할 수 있는지 보겠습니다.
1. find()와 findAll()
두 함수는 아래와 같은 매개변수를 가집니다.
ㅇfindAll(tag, attributes, recursive, text, limit, keywords)
ㅇfind(tag, attributes, recursive, text, keyworkds)
tag 찾으려는 태그 이름을 지정하며, div태그를 지정할땐 tag='div' 이렇게 설정 attributes 특정 속성을 가진 태그를 필터링할 때 사용됩니다. 예를 들어, 클래스가 title인 <div> 태그를 찾으려면 attributes={'class': 'title'}로 설정 recursive True 또는 False 값을 가질 수 있습니다. True로 설정하면 모든 자식 태그를 재귀적으로 검색하고, False로 설정하면 바로 하위 자식들만 검색합니다. text 태그 내부의 텍스트를 필터링하는 데 사용합니다. 특정 텍스트를 포함하는 태그만 찾고 싶을 때 유용합니다. limit 검색 결과 개수를 제한합니다. 예를 들어, limit=5로 설정하면 검색된 첫 5개의 요소만 반환합니다. keywords 추가적인 키워드 인수를 사용하여 특정 속성을 찾을 때 유용합니다. BeautifulSoup는 이 인수를 통해 편리하게 필터링을 지원합니다.

복잡한 태그를 만나면 당장 달려들어 여러 줄의 코드를 써서라도 정보를 추출하기 보다는
효과적으로 필요한 결과를 얻을 수 있는 방법을 학습했습니다.
과거 저는 아래와 같은 식으로 네이버 금융을 크롤링을 하여 데이터를 가져와서 프로젝트라고 제출한적이 있습니다.
bs.findAll('table')[4].find_all('tr')[2].find('td').find_all('div')[1].find('a')간결함이나 우아함은 찾아볼 수 없으뿐더러, 사이트 관리자가 사이트를 조금만 수정하더라도 웹 크롤링의 동작이 멈출 수 있습니다.
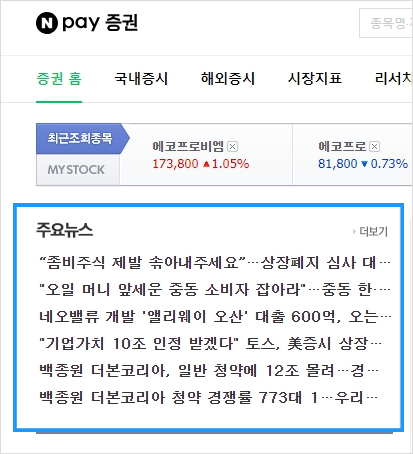
이 화면의 뉴스헤드라인만 가져오고 싶다면 아래와 같이 작성할 수 있습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://finance.naver.com/')
bs = BeautifulSoup(html, 'html.parser')
nameList = bs.findAll('div', {'class': 'section_strategy'})
for name in nameList:
li_tags = name.findAll('li')
for li in li_tags:
print(li.get_text())
이렇게 출력될 수 있습니다.
find() 와 findAll()는 BeaotifulSoup에서 가장 자주 쓰는 함수입니다. 이 함수를 쓰면 HTML페이지에서 원하는 태그를 다양한 속성에 따라 쉽게 필터링 할 수 있습니다.
이제 조금씩 속성을 이용해서 위의 결과가 어떻게 변하는지 확인해보겠습니다.
재귀를 False로 했을때
nameList = bs.findAll('div', {'class': 'section_strategy'},False)
텍스트 조건을 주었을때
nameList = bs.findAll(string='삼성전자')
Limit을 통해 출력 개수 제한하기
nameList = bs.findAll('img', limit=5)
2. 자식과 자손, 형제 다루기
조금 복잡해지는 html 구조에는 부모와 형제 자식과 자손이 있습니다.
자식은 항상 부모보다 한 태그 아래에 있고, 자손은 조상보다 몇 단계 아래에 있을 수 있습니다.
자식과 자손 다루기
이제 앞선 예제에서 네이버금융의 뉴스쪽 div태그의 자식만 가져오는 방식으로 구현해보겠습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://finance.naver.com/')
bs = BeautifulSoup(html, 'html.parser')
for child in bs.find('div', {'class':'section_strategy'}).children:
print(child)
이 코드는 네이버금융의 뉴스가 있는 목록을 출력합니다. childern() 대신 descendants를 사용했다면 더 많은 태그가 출력됩니다.
형제 다루기
next_siblings() 함수를 이용해서 테이블에서 데이터를 쉽게 수집할 수 있습니다.

이런 테이블 형태의 데이터를 가져 보다 쉽게 수집할 수 있습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://finance.naver.com/')
bs = BeautifulSoup(html, 'html.parser')
for sb in bs.find('tbody', {'id':'_topItems1'}).tr.next_siblings:
print(sb)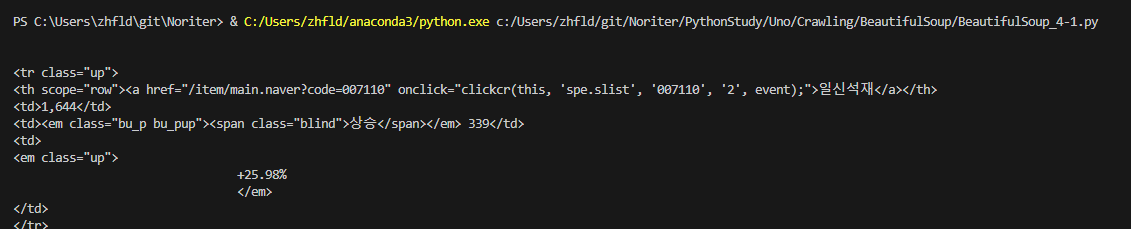
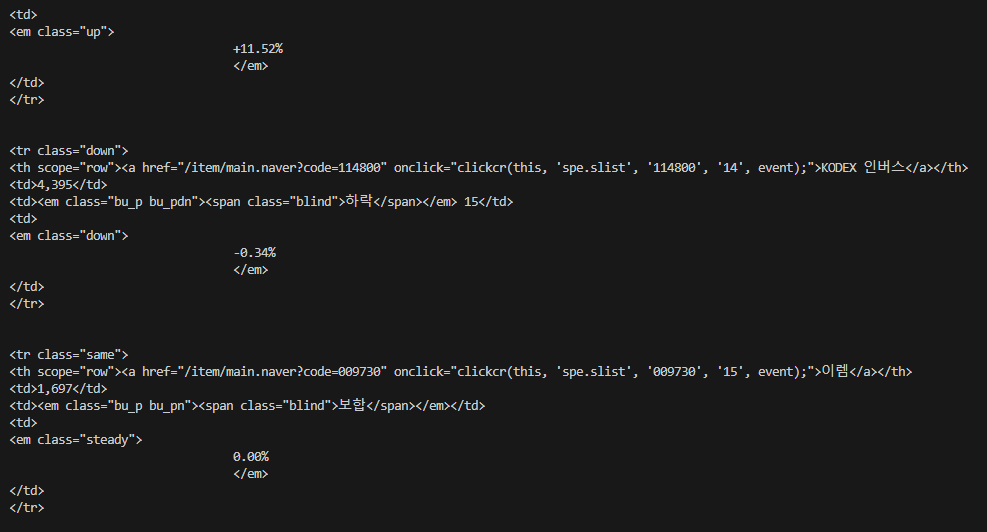
이렇게 출력됩니다. 이때 조금만 데이터를 정제한다면 우리가 필요한 정보만 가져올 수 있게됩니다.
거래상위 종복 테이블에서 첫 번째 타이틀 행을 제외한 모든 주식 행입니다. 엄밀히 말하면 모든 주식은 아닙니다.
타이틀행을 건너뛰었으니까요, 이렇게 형제로 객체를 넘기는 것을 쓴다면, 자기 자신을 형제가 될 수 없기에 넘어가게 됩니다.
즉 객체의 형제를 가져올 때, 객체 자체는 항상 그 목록에서 제외 합니다. 함수 이름이 암시하듯, 이 함수는 다음 형제만 가져온다는 것을 알 수 있습니다.
그래서 그 행을 선택하고 next_siblings를 호출한다면 그 다음에 있는 형제들만 반환됩니다.
따라서 맨위에는 코덱스 선물 200 인버스 곱 이 아닌 일신석재가 되게됩니다.
부모 다루기
페이지를 크롤링하다보면 자식이나 형제뿐만아니라 부모를 찾아야할 때가 있습니다.
html구조상 위 계층으로 이동하여 또 원하는 데이터까지 어떻게 찾아 들어갈지 고민이 필요합니다.
그래서 parent 함수가 필요합니다.

from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://finance.naver.com/')
bs = BeautifulSoup(html, 'html.parser')
list = bs.find(string='국제 시장 환율').parent.parent.next_siblings
for s in list:
print(s)국제 시장 환율의 정보를 얻기위해서 국제 시장 환율 텍스트만 찾은다음 그것의 부모의 부모의 구조를 통해 찾고 진행해봤습니다.

정보가 모두 나왔습니다.