3. LLM의 활용과 학습 과정: 이론적 접근과 응용
1. LLM을 활용하는 방법
LLM을 효과적으로 활용하는 방법은 여러 가지가 있으며, 각 방식은 기존 모델을 어떻게 조정하느냐에 따라 다릅니다. 대표적으로 전이 학습(Transfer Learning), 파인튜닝(Fine-Tuning), 검색 증강 생성(RAG), 그리고 Few-shot Learning이 있습니다.
1-1. 전이 학습(Transfer Learning)과 파인튜닝(Fine-Tuning)
LLM의 활용 방식은 크게 전이 학습과 파인튜닝으로 나뉩니다.
- 전이 학습 (Transfer Learning)
기존의 사전 훈련된 모델을 새로운 작업에 맞게 조정하는 방법.- 전체 모델 가중치를 유지하면서 일부 특정 계층(layer)만 조정.
- 예제: BERT → BioBERT (의료 논문 분석용으로 학습된 모델)
- 파인튜닝 (Fine-Tuning)
사전 훈련된 모델을 특정 도메인 데이터로 다시 학습하는 방식.- 전체 가중치를 변경하며, 특정 태스크(예: 법률 문서 분석)에 최적화.
- 예제: GPT-3 → InstructGPT (사람의 피드백을 학습한 LLM)
(1) 수식으로 전이 학습과 파인튜닝 차이 이해
전이 학습에서는 기존 모델 fθf_{\theta}를 기반으로 새로운 작업 T′T'에 대해 학습하는데,
목표는 사전 학습된 분포 p(w)p(w)를 유지하면서 새로운 작업 p′(w)p'(w)로 조정하는 것입니다.

- L : 손실 함수 (Cross-Entropy 손실 등)
- R(θ) : 정규화 항 (L2 정규화 등)
- λ : 정규화 강도
전이 학습에서는 R(θ)R(\theta)를 통해 기존 가중치가 급격히 변하는 것을 방지하는 것이 핵심입니다.
1-2. RAG(Retrieval-Augmented Generation)
LLM의 성능을 향상시키기 위해 검색 증강 생성(RAG, Retrieval-Augmented Generation) 기법이 활용됩니다. 이는 모델이 외부 지식을 검색하고 활용하여 더 정확한 출력을 생성하는 방식입니다.
(1) 정보 검색 단계
RAG 모델은 주어진 질문 QQ에 대해 가장 관련성이 높은 문서 DD를 검색합니다. 이때 사용되는 대표적인 검색 기법은 다음과 같습니다.
- BM25: 단어 빈도 기반 전통적인 검색 방법
- DPR(Dense Passage Retrieval): 문서 임베딩을 활용한 딥러닝 기반 검색
- FAISS (Facebook AI Similarity Search): 고속 벡터 검색을 지원하는 라이브러리
문서 검색 과정은 확률적으로 표현될 수 있습니다.
주어진 질문 QQ에 대해 문서 DD가 선택될 확률은 다음과 같습니다.

여기서,
- sim(Q,D)는 질문과 문서 간의 유사도를 나타냅니다 (예: 코사인 유사도, 내적).
- 분모는 모든 문서 D에 대한 확률을 정규화한 값입니다.
(2) 텍스트 생성 단계
문서 검색이 완료되면, LLM은 검색된 문서를 활용하여 최종 답변을 생성합니다.
이 과정은 기본적인 언어 모델 P(wt∣w1:t−1)P(w_t | w_{1:t-1})에 검색된 문서 정보를 추가적으로 반영하는 방식입니다.
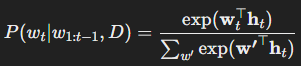
- : Transformer의 현재 상태(hidden state)
- wt : 예측할 단어 wtw_t의 임베딩
- D : 검색된 문서에서 제공한 추가 컨텍스트
1-3. Few-shot Learning과 One-shot Learning
LLM은 학습 데이터를 추가로 제공하지 않고도, 몇 개의 예제(Few-shot)를 입력하면 새로운 태스크를 수행할 수 있습니다.
- Few-shot Learning: 몇 개의 예제를 제공한 후 LLM이 패턴을 학습
- One-shot Learning: 하나의 예제만 제공해도 모델이 태스크를 수행
- Zero-shot Learning: 예제 없이도 기존 지식을 활용하여 수행
이 원리는 메타 학습(Meta Learning)과 연결됩니다. 즉, LLM이 기존 학습된 분포를 일반화하여 새로운 태스크에 빠르게 적응하는 과정입니다.