[ONLY JAVA-Crowling/File] 자바 웹 크롤링(이미지 크롤링) + HttpUrlConnection이용해서 간단한 파일 다운로드 프로그래밍
개요
특정 사이트의 이미지를 모두 긁어와 특정 로컬 폴더에 패턴을 적용하여 적용하는 프로그램을 구현했습니다.
주로 사용된 기술과 스킬은 아래와 같습니다.
- HttpURLConnection을 이용해 URL에 접속해 해당 페이지의 데이터를 획득
- html의 구조와 태그에 대해 이해
- 파일 스트림에 대한 이해와 응용으로 이미지파일 생성
- 파일 클래스에 대한 이해와 응용으로 로컬에 파일 저장
내용
23.12.02 소스를 수정하였습니다.
- 스윙으로 GUI개선
- URL와 폴더 선택가능
- 실시간 처리확인 기능
변경된 소스 접은글입니다.
소스
package Java.Crawling;
import java.awt.Desktop;
import java.awt.FlowLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import javax.swing.JButton;
import javax.swing.JFileChooser;
import javax.swing.JFrame;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTextField;
import javax.swing.SwingUtilities;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class CrawlingNaverFins extends JFrame {
/**
*
*/
private static final long serialVersionUID = 1L;
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
/* 현재 과업(과제)구분을 위한 상수형 */
final static String TASK_ID = "MyPost";
/* 파일이 생성될 곳의 주소, 실경로를 설정 */
final static String SAVE_DIR = "C:\\Users\\zhfld\\downloads\\img";
/* 이미지파일 확장자 */
final static String IMG_EXT = ".png";
/* 파일명 구분자 */
final static String FILE_SEPARATOR = "_";
/* 버퍼사이즈 맥스로 주고 상수형으로 관리 */
final static int BUFFER_SIZE = 4096;
/* 이미지 태그 */
final static String TAG_IMG = "img";
/* 소스 속성(attribute) */
final static String ATTR_SRC = "src";
private final JTextField urlField;
private final JButton downloadButton;
private final JTextArea resultArea;
private JButton selectFolderButton; // 새로 추가된 버튼
private String saveDir; // 저장될 폴더 경로
public CrawlingNaverFins() {
super.setTitle("이미지 다운로더");
super.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
super.setSize(400, 300);
super.setLayout(new FlowLayout());
urlField = new JTextField(URL_STRING, 30);
super.add(urlField);
downloadButton = new JButton("다운로드");
super.add(downloadButton);
resultArea = new JTextArea(10, 30);
resultArea.setEditable(false);
JScrollPane scrollPane = new JScrollPane(resultArea);
super.add(scrollPane);
selectFolderButton = new JButton("폴더 선택");
super.add(selectFolderButton);
selectFolderButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
selectFolder();
}
});
JButton openFolderButton = new JButton("폴더 열기");
openFolderButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
openFolder();
}
});
super.add(openFolderButton);
downloadButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
String urlString = urlField.getText().trim();
downloadImages(urlString);
}
});
}
private void selectFolder() {
JFileChooser fileChooser = new JFileChooser();
fileChooser.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY);
int result = fileChooser.showOpenDialog(this);
if (result == JFileChooser.APPROVE_OPTION) {
File selectedFolder = fileChooser.getSelectedFile();
saveDir = selectedFolder.getAbsolutePath();
showMessage("저장 폴더 선택: " + saveDir);
}
}
private void openFolder() {
if (saveDir != null && !saveDir.isEmpty()) {
try {
Desktop.getDesktop().open(new File(saveDir));
} catch (IOException e) {
showMessage("폴더 열기 실패: " + e.getMessage());
}
} else {
showMessage("먼저 폴더를 선택하세요.");
}
}
private void downloadImages(String urlString) {
if (urlString.isEmpty()) {
showMessage("URL을 입력하세요.");
return;
}
try {
Document document = Jsoup.connect(urlString).get();
Elements images = document.select(".contents_style").select(TAG_IMG);
int successCount = 0;
for (int i = 0; i < images.size(); i++) {
String connImgUrl = images.get(i).attr(ATTR_SRC);
HttpURLConnection connUrl = (HttpURLConnection) new URL(connImgUrl).openConnection();
if (connUrl.getResponseCode() == HttpURLConnection.HTTP_OK) {
String fileName = "MyPost" + FILE_SEPARATOR
+ LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy_MM_dd")) + FILE_SEPARATOR + i
+ IMG_EXT;
FileOutputStream fileOutputStream = new FileOutputStream(new File(SAVE_DIR, fileName));
InputStream inputStream = connUrl.getInputStream();
byte[] bufferArr = new byte[BUFFER_SIZE];
int bytesData;
while ((bytesData = inputStream.read(bufferArr)) != -1) {
fileOutputStream.write(bufferArr, 0, bytesData);
}
fileOutputStream.close();
inputStream.close();
showMessage(fileName + " 저장 성공");
successCount++;
} else {
showMessage(i + "번째 이미지 URL 접속 실패");
}
}
showMessage("총 " + successCount + "개의 이미지 다운로드 완료");
} catch (IOException e) {
showMessage("오류 발생: " + e.getMessage());
}
}
private void showMessage(String message) {
resultArea.append(message + "\n");
}
public static void main(String[] args) {
SwingUtilities.invokeLater(() -> {
CrawlingNaverFins downloaderApp = new CrawlingNaverFins();
downloaderApp.setVisible(true);
});
}
}변경된 이후 프로그램 동작화면입니다.
이전 내용
안녕하세요~!!! 지난 포스팅으로는
웹 크롤링(이미지 크롤링) + HttpUrlConnection이용해서 간단한 파일 다운로드
Jsoup 라이브러리를 이용해서 원하는 데이터들을 쏙쏙! 뽑아오고 그것을 콘솔을 통해서
확인하였습니다.
이제 이번엔 간단하게 크롤링을 하여서 가져온 데이터나 소스들을 응용하는 방법에 대해 알아보겠습니다!!!
실제 소스 구현한 화면과 콘솔 그리고 설명, 소스코드 까지 모두 글에 담아냈습니다. 천천히 읽어보시면서 따라하시면 모두 구현하고 응용까지 가능하게 설명해드렸으니 끝까지 읽어주세요~!
특히 이미지 소스들을 크롤링 하는 방법에 대해서 간단하게 알아보겠습니다.

지난 Jsoup 라이브러리 설치하러가기 : https://uno-kim.tistory.com/213
[JAVA]Jsoup 라이브러리를 이용한 크롤링 - Jsoup 사용법 + 라이브러리 저장하는 법
안녕하세요~! ㅎㅎ 오늘 포스팅은 그동안 크롤링를 하여 네이버 금융의 정보를 가져왔었는데 크게 사용되었던 라이브러리인 Jsoup 라이브러리 사용법 에 대해서 알아보겠습니다! 1. 라이브러리
uno-kim.tistory.com
지난 Jsoup 라이브러리 간단한 사용법 : https://uno-kim.tistory.com/215
[JAVA]Jsoup 라이브러리를 이용한 크롤링 - Jsoup 사용법
안녕하세요! 오늘 포스팅은 Jsoup 라이브러리를 알아보려고 해요 해당 라이브러리는 가장 편한 API 를 제공하며 HTML5 DOM 메서드와 CSS 선택기를 사용하여, URL을 가져오고 데이터를 추출 및 조작하기
uno-kim.tistory.com
우선 아래 순서로 진행하겠습니다.
1. Jsoup라이브러리를 통해서 이미지소스를 가져온다.
2. 쌩자바(HttpUrlConnection)클래스를 이용해서 해당 소스 Url에 접속한다.
3. I/O 클래스를 이용해서 간단하게 파일을 원하는 디렉터리에 생성시킨다.
우선 저희는 간단하게 웹 크롤링(이미지 크롤링) + HttpUrlConnection이용해서 간단한 파일 다운로드 진행하기 위해서
제 포스팅의 이미지들을 전부 가져오는 것으로 진행하겠습니다.

예시를 들기위해서 다른 이미지를 가져오기에는 저작권문제도 있고 또 어떤일들이 발생할 지 모르니
https://uno-kim.tistory.com/215
위 사이트의 사진들을 전부 가져오는 것으로 실습진행해보겠습니다.
최초 저희는 Jsoup을 통해서 우리가 원하는 이미지 파일의 소스를 가져와야합니다.!!!

먼저 제 포스팅의 이미지 소스들만 콘솔에 출력시켜보겠습니다.
[제 포스팅을 연결하고 이미지 소스만 가져오는 소스]
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlingNaverFins
{
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
public static void main(String[] args) throws IOException
{
Document document = Jsoup.connect(URL_STRING).get();
for (int i = 0; i < document.select("img").size(); i++)
{
System.out.println(i + ". : " + document.select("img").get(i));
}
}
}
소스를 실행한 결과입니다.
1번부터 쭉돌아서 총 45개의 이미지 태그들만 쫙 골라서 가져왔습니다.
그런데 말입니다. 사실 제가 올린 사진이 그렇게 많지 않은데
45개씩이나 나오다니 잠깐 의심을 해보겠습니다.
확인해보니

하단의 썸네일 부분이라던가 제 블로그의 대표 이미지?
등까지 모두 출력 시킨 결과였습니다.
따라서 우리는 원하는 섹션, 구획의 내부 이미지들을 가져와야합니다.
우리는

본문부분의 contents_style클래스를 가져오고 해당 클래스 내부의 이미지 태그를 사용해야합니다.
이를 소스에 적용시켜보겠습니다.
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlingNaverFins
{
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
public static void main(String[] args) throws IOException
{
Document document = Jsoup.connect(URL_STRING).get();
for (int i = 0; i < document.select(".contents_style").select("img").size(); i++)
{
System.out.println(i + ". : " + document.select(".contents_style").select("img").get(i));
}
System.out.println("::SysOut End::");
}
}
이렇게 총 제가 올린 이미지 26개의 이미지 태그만 가져왔습니다!!!
어우 불필요한게 19개나 되었다니... 속을뻔했네요 ㅎㅎ

이제 여기서 우리가 필요한 이미지 URL인 src 속성의 값만 또 가져와야합니다.
그러기 위해서 다음 소스를 더 추가해 주겠습니다.!!!
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlingNaverFins
{
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
public static void main(String[] args) throws IOException
{
Document document = Jsoup.connect(URL_STRING).get();
for (int i = 0; i < document.select(".contents_style").select("img").size(); i++)
{
System.out.println(
/*Print Seq : 출럭 시퀀스를 담당하는 부분*/
i + ". : "
/* 가져올 클래스를 선언해주는 부분 */
+ document.select(".contents_style")
/* 가져올 이미지 태그를 선언해주는 부분 */
.select("img").get(i)
/* 가져온값에서 src 부분의 텍스트 부분을 가져오는 부분 */
.attr("src"));
}
System.out.println("::SysOut End::");
}
}친절하게 주석으로 다달아봤구요. 통째로 복사를 해서 보신다면
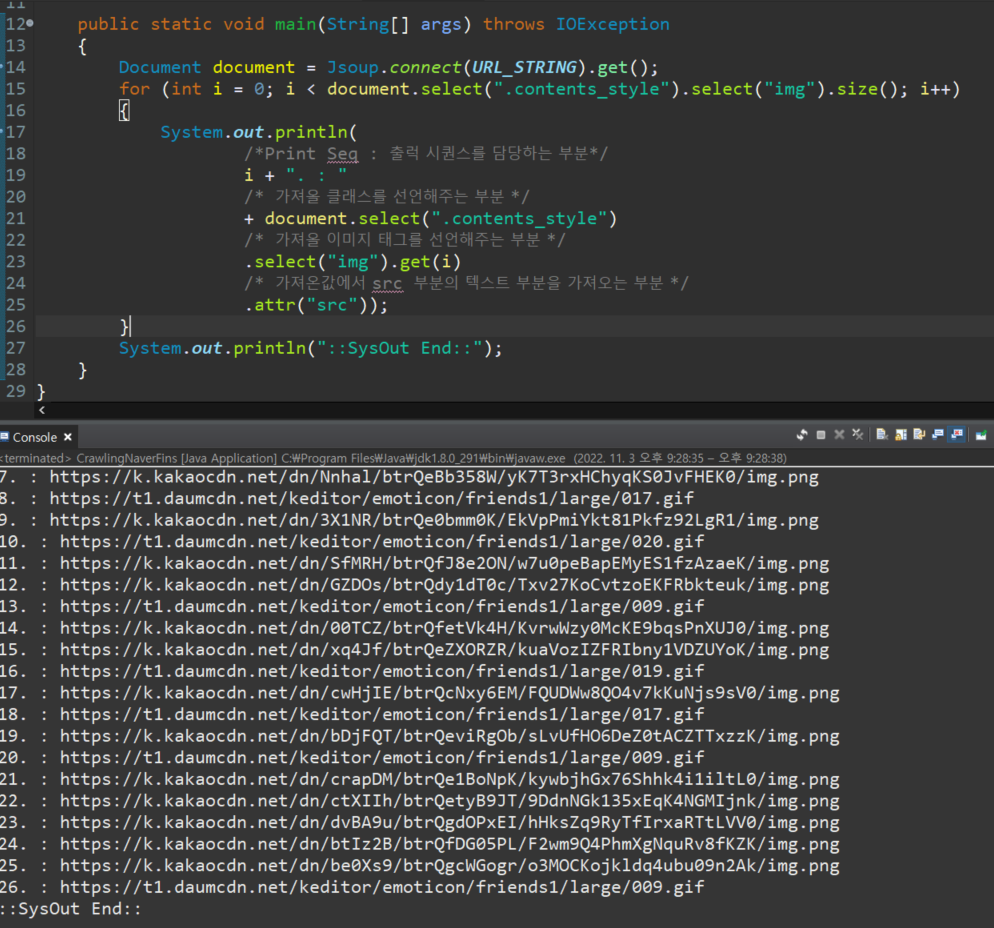
와우!!!

이제 완전 깔끔?? 한 이미지 소스만 가져왔습니다!!!
이제 이 소스들을 하나하나 값이 유효한지에 대해 확인하러 다음단계로 이동하겠습니다!!
2. 쌩자바(HttpUrlConnection)클래스를 이용해서 해당 소스 Url에 접속
이번 단계는 조금 간단할 수 있습니다.
우선 쌩자바(특정 외부 라이브러리를 사용하지 않고 기본 자바 클래스를 이용해서 구현하는 코딩??)을 주로
쌩자바 쌩자바 이렇게 부르더라구요,
그래서 이번엔 Url 과 HttpUrlConnection 클래스를 이용해서
해당 이미지소스 Url 에 접속하고 접속 성공유무를 반환 받는 것까지 해보겠습니다.!!
기존 소스에서 계속 추가를 해주게 되어 소스가 길어질 수 있으니 주의해주세요!!!
package ㅎJavaTests;
import java.io.IOException;
import java.net.HttpURLConnection;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlingNaverFins
{
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
public static void main(String[] args) throws IOException
{
Document document = Jsoup.connect(URL_STRING).get();
for (int i = 0; i < document.select(".contents_style").select("img").size(); i++)
{
String connImgUrl = document.select(".contents_style").select("img").get(i).attr("src");
try
{
URL url = new URL(connImgUrl);
HttpURLConnection connUrl = (HttpURLConnection) url.openConnection();
int responseCode = connUrl.getResponseCode();
// Status 가 200 일 때
if(responseCode == HttpURLConnection.HTTP_OK)
{
System.out.println("### " + i + "번째 이미지 URL 접속 성공");
}
else
{
System.out.println("--- " + i + "번째 이미지 URL 접속 실패");
}
System.out.println();
}
catch (Exception e)
{
System.out.println(":::::: 오류 발생 ::::::");
System.out.println(e.getMessage());
}
}
System.out.println("::Test End::");
}
}HttpUrlConnection 클래스를 통해서 연결 했습니다.
URL 클래스를 이용했습니다. url 객체를 생성하고
이를 통해서 HttpURLConnection 객체도 만들어주었고
(HttpURLConnection) url.openConnection(); 이 메서드를 통해서
이미지 Url에 접속을 하게됩니다.
그리고 그 정보들은 connUrl 에 들어오게됩니다.
그래서
응답값 (404,500,200,403,400 등등등...) 을 확인하는 메서드인 connUrl.getResponseCode()
이 함수를 통해서 200일 경우 성공한것으로 간주하고 결과를 출력시키도록 하였습니다.
과연... 결과는...?
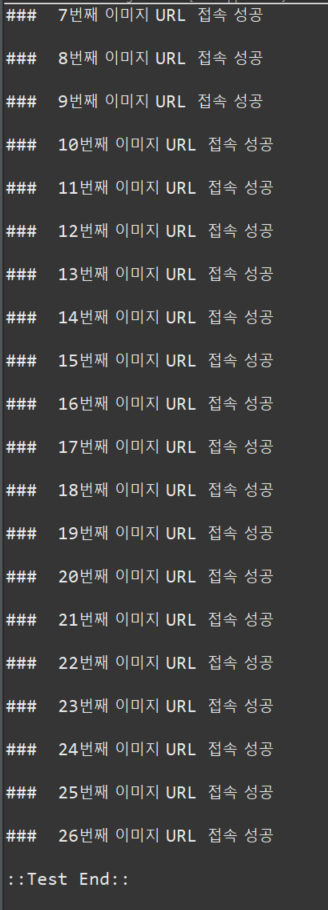
짜잔!! 모두 연결 성공!!!
이제 연결이 모두 되었으니 I/O 클래스를 이용해서 이제 다운로드를 하고 파일을 생성해보겠습니다.!!!
3. I/O 클래스를 이용하여 파일 다운로드하기
이제 우리는 Stream 을 통해서 다운로드를 진행하는 단계에 왔습니다.!!!

이제 얼마 안남았습니다!!
ㅎㅎㅎ
우선 이 단계에서 해야할 순서로는
1. 파일명 패턴으로 관리하기
2. InputStream -> FileOutputStream을 통해서 파일을 생성/ 다운로드
이렇게 2개의 순서로 진행하겠습니다.
[1] 파일명 패턴 적용하여 관리하기
파일명을 우선 현재 과제이름+날짜 로 주로 저장하는 경향이 있어서 그렇게 진행해보겠습니다!!
우선 소스는 아래와 같이 작성했습니다.
package ㅎJavaTests;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlingNaverFins
{
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
/* 현재 과업(과제)구분을 위한 상수형 */
final static String TASK_ID = "MyPost";
public static void main(String[] args) throws IOException
{
Document document = Jsoup.connect(URL_STRING).get();
for (int i = 0; i < document.select(".contents_style").select("img").size(); i++)
{
String connImgUrl = document.select(".contents_style").select("img").get(i).attr("src");
try
{
URL url = new URL(connImgUrl);
HttpURLConnection connUrl = (HttpURLConnection) url.openConnection();
int responseCode = connUrl.getResponseCode();
// Status 가 200 일 때
if(responseCode == HttpURLConnection.HTTP_OK)
{
/* 오늘 날짜를 파일명에 명명해주기위한 날짜 객체 선언 */
LocalDate now = LocalDate.now();
/* 특정날짜 포맷을 주기위한 포맷객체 선언 */
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy_MM_dd");
/* 포맷적용 */
String formatedNow = now.format(formatter);
/* 과업(과제) + 날짜를 파일명으로 명명 */
String fileName = TASK_ID + "_" + formatedNow + "_" + i;
System.out.println(fileName);
}
else
{
System.out.println("--- " + i + "번째 이미지 URL 접속 실패");
}
System.out.println();
}
catch (Exception e)
{
System.out.println(":::::: 오류 발생 ::::::");
System.out.println(e.getMessage());
}
}
System.out.println("::Test End::");
}
}LocalDate now = LocalDate.now(); 를 통해서 오늘 날짜를 가져왔으며
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy_MM_dd");를 통해서 포맷을 변경!
String formatedNow = now.format(formatter); 를 통해서 포맷을 적용한 문자열 생성!
그리고 파일이름을 시퀀스와 조합하여
출력을 하게되었더니


와우!!!
파일명이 정상적으로 적용이 된것을 확인 할 수 있습니다!!!
[2] Stream을 통한 다운로드
이젠 대망의 마지막단계의 마지막 순서인 Stream을 이용한 다운로드입니다. 두구두구두구..!!!
package ㅎJavaTests;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlingNaverFins
{
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
/* 현재 과업(과제)구분을 위한 상수형 */
final static String TASK_ID = "MyPost";
/* 파일이 생성될 곳의 주소, 실경로를 설정 */
final static String SAVE_DIR = "C:\\Users\\zhfld\\downloads";
/* 버퍼사이즈 맥스로 주고 상수형으로 관리 */
final static int BUFFER_SIZE = 4096;
public static void main(String[] args) throws IOException
{
Document document = Jsoup.connect(URL_STRING).get();
for (int i = 0; i < document.select(".contents_style").select("img").size(); i++)
{
String connImgUrl = document.select(".contents_style").select("img").get(i).attr("src");
try
{
URL url = new URL(connImgUrl);
HttpURLConnection connUrl = (HttpURLConnection) url.openConnection();
int responseCode = connUrl.getResponseCode();
if(responseCode == HttpURLConnection.HTTP_OK)
{
/* naming Start */
LocalDate now = LocalDate.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy_MM_dd");
String formatedNow = now.format(formatter);
String fileName = TASK_ID + "_" + formatedNow + "_" + i;
/* naming End */
/* Stream Start */
File file = new File(SAVE_DIR, fileName);
FileOutputStream fileOutputStream = new FileOutputStream(file);
InputStream inputStream = connUrl.getInputStream();
byte[] bufferArr = new byte[BUFFER_SIZE];
int bytesData = 0;
while ((bytesData = inputStream.read(bufferArr)) != -1)
{
fileOutputStream.write(bufferArr, 0, bytesData);
}
fileOutputStream.close();
inputStream.close();
/* Stream End */
System.out.println(fileName + " 저장성공");
}
else
{
System.out.println("--- " + i + "번째 이미지 URL 접속 실패");
}
System.out.println();
}
catch (Exception e)
{
System.out.println(":::::: 오류 발생 ::::::");
System.out.println(e.getMessage());
}
}
System.out.println("::Test End::");
}
}이제 거의 완성된 소스입니다.
소스 부연설명을 드리자면
우선 상수형 선언부에 파일이 생성될 제 로컬 주소, 그리고 버퍼사이즈를 최대로 설정한 것을 상수형으로 관리합니다.
그리고 실제 Stream 구현부는
파일 클래스와 FileOutputStream, InputStream 를 사용했습니다.
파일클래스를 사용한 것은 간단하게 설명드리자면 저장할 주소와 해당 파일 이름을 지정하고 생성하기 위해서 입니다.
그리고 connUrl.getInputStream() 를 이용해서 이미지 Url 의 인풋스트림을
fileOutputStream에 while를 통해 바이트 정보를 모두 작성해주는 과정을 통하게됩니다.
이것을 자세히 설명드리기엔 너무많아져 대략적으로 눈으로 볼 수 있는 정도로 설명드리자면

소스중 출력문을 통해 FIle 객체 생성한 직후 용량과
while문 이후 용량 비교를 통해서 확인만하고 넘어가겠습니다.!!!

정확한 비교이거나 설명인지는 잘모르겠지만 (아니라면 댓글달아주세요...ㅠㅠ)
이렇게 차이가 납니다.
이제 소스를 조금 가다듬고, 확장자 도 어짜피 저희는 이미지 이니 상수형으로 해당 확장자를 관리하여
소스를 보시면
최종소스입니다.
package ㅎJavaTests;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlingNaverFins
{
/* 실습을 위한 상수형의 Url 주소 : 내 티스토리 포스팅 주소 */
final static String URL_STRING = "https://uno-kim.tistory.com/215";
/* 현재 과업(과제)구분을 위한 상수형 */
final static String TASK_ID = "MyPost";
/* 파일이 생성될 곳의 주소, 실경로를 설정 */
final static String SAVE_DIR = "C:\\Users\\zhfld\\downloads";
/* 이미지파일 확장자 */
final static String IMG_EXT = ".png";
/* 파일명 구분자 */
final static String FILE_SEPARETE = "_";
/* 버퍼사이즈 맥스로 주고 상수형으로 관리 */
final static int BUFFER_SIZE = 4096;
/* 이미지 태그 */
final static String TAG_IMG = "img";
/* 소스 속성(attribute) */
final static String ATTR_SRC = "src";
public static void main(String[] args) throws IOException
{
Document document = Jsoup.connect(URL_STRING).get();
for (int i = 0; i < document.select(".contents_style").select(TAG_IMG).size(); i++)
{
String connImgUrl = document.select(".contents_style").select(TAG_IMG).get(i).attr(ATTR_SRC);
try
{
HttpURLConnection connUrl = (HttpURLConnection) new URL(connImgUrl).openConnection();
if(connUrl.getResponseCode() == HttpURLConnection.HTTP_OK)
{
String fileName = TASK_ID + FILE_SEPARETE + LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy_MM_dd")) + FILE_SEPARETE + i
+ IMG_EXT;
FileOutputStream fileOutputStream = new FileOutputStream(new File(SAVE_DIR, fileName));
InputStream inputStream = connUrl.getInputStream();
byte[] bufferArr = new byte[BUFFER_SIZE];
int bytesData = 0;
while ((bytesData = inputStream.read(bufferArr)) != -1)
{
fileOutputStream.write(bufferArr, 0, bytesData);
}
fileOutputStream.close();
inputStream.close();
/* Stream End */
System.out.println(fileName + " 저장성공");
}
else
{
System.out.println(i + "번째 이미지 URL 접속 실패");
}
}
catch (Exception e)
{
System.out.println(":::::: 오류 발생 ::::::");
System.out.println(e.getMessage());
}
}
System.out.println("::Test End::");
}
}[실행한 콘솔결과]
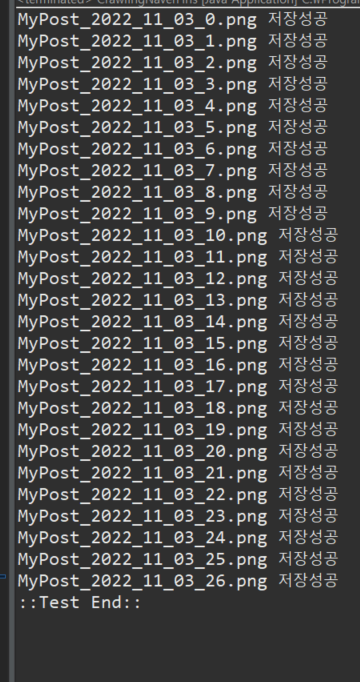
[실제 파일 저장된 결과]
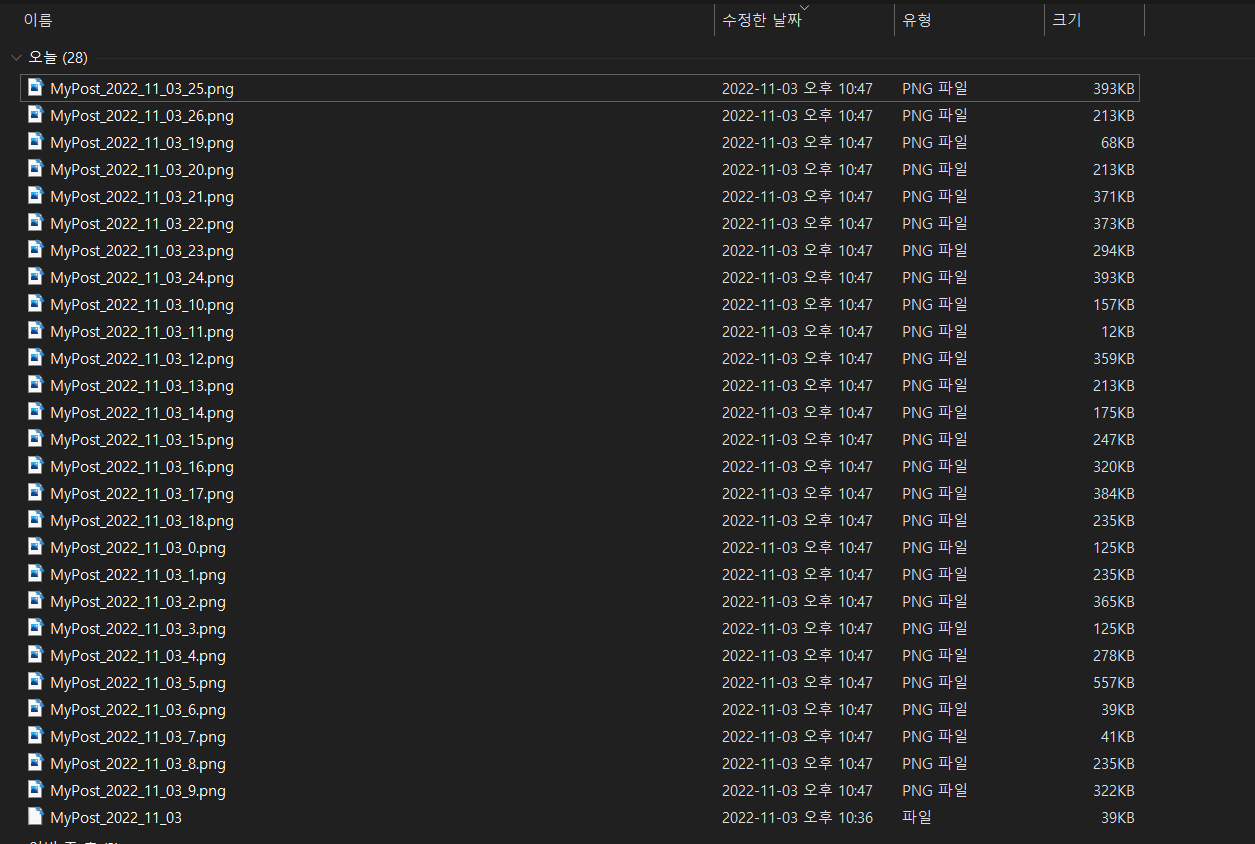
대!성!공!!!
변경될일이 없는 것은 상수형으로 관리하였습니다.
고정적으로 사용되는 것은 상수형으로 관리하는게 좋다고 생각하고
클래스 명의 경우 매개변수로 받아와서 상황에 따라 변경되고 다른 값이 들어올 경우가 많으니
상수형으로 관리하지 않았습니다. 이 외에는 태그, 속성명, 구분자, 저장경로, 사이트 등등은 고정적으로 쓰게 하였습니다.
물론 사이트도 매개변수로 받아와 사용한다면 상수형에서 제거해야겠지만요 ㅎㅎㅎ
1. Jsoup을 통해서 원하는 주소와 태그 그리고 속성의 주소값을 가져온다.
2..바로 HttpURLConnection 통해서 이미지 소스에 접속
3. 성공여부에 따라 특정 패턴 적용한 파일명 생성
4. 생성된 파일명으로 파일 생성
총 이렇게 진행하였고 모두 성공하였습니다.
이 기법은 아주 중요한 기초라고 생각합니다.
이것으로 개인 프로젝트 진행이나 대강 파일 시스템 그리고 Url 접속 통신접속 등
기술적인 측면으로 이런게 있구나 정도로 알고 진행하시면 될것같습니다.
긴글 읽어주셔서 감사힙니다.
웹 크롤링(이미지 크롤링) + HttpUrlConnection이용해서 간단한 파일 다운로드