getElement.... attribute 어쩌고... 이렇게 한다면 조금 어렵게 느껴지실 수 있다고 생각하고
저도 은근 그게 편하다고 생각해서 그렇게 했습니다.
크게 파싱하는 방법에 대해서 정답은 없습니다. 다만 예외가 가장적으며 빠르고, 간단명료한 소스가 좋은 소스라고 생각하기에 이용자에 맞는 소스를 작성하기만 하면될 것같습니다.
또는 회사나 단체의 규칙을 지키면 될 것 같습니다.
이번에 설명드릴것은
select() 메소드 입니다.
??? : 겨우 메소드 하나쓰는데 기타등등이라고 하고 혼자 무슨 필살기마냥 설명하는거냐
라고 생각 하실 수 있는데 거의 맞습니다.
왜냐하면 해당 select 기능이 querySelector 의 기능과 흡사하며 , 더욱 강력하고 넓은 기능을 구현 할 수있기 때문입니다.
그게 무슨 말이냐면
select만 사용해서 우리가 원하는 단계와 객체까지 접근이 가능합니다.
1. 태그 명만 썼을때
document.select("img")
2. 클래스명을 "." 붙여서 썼 을 때
document.select(".section_strategy")
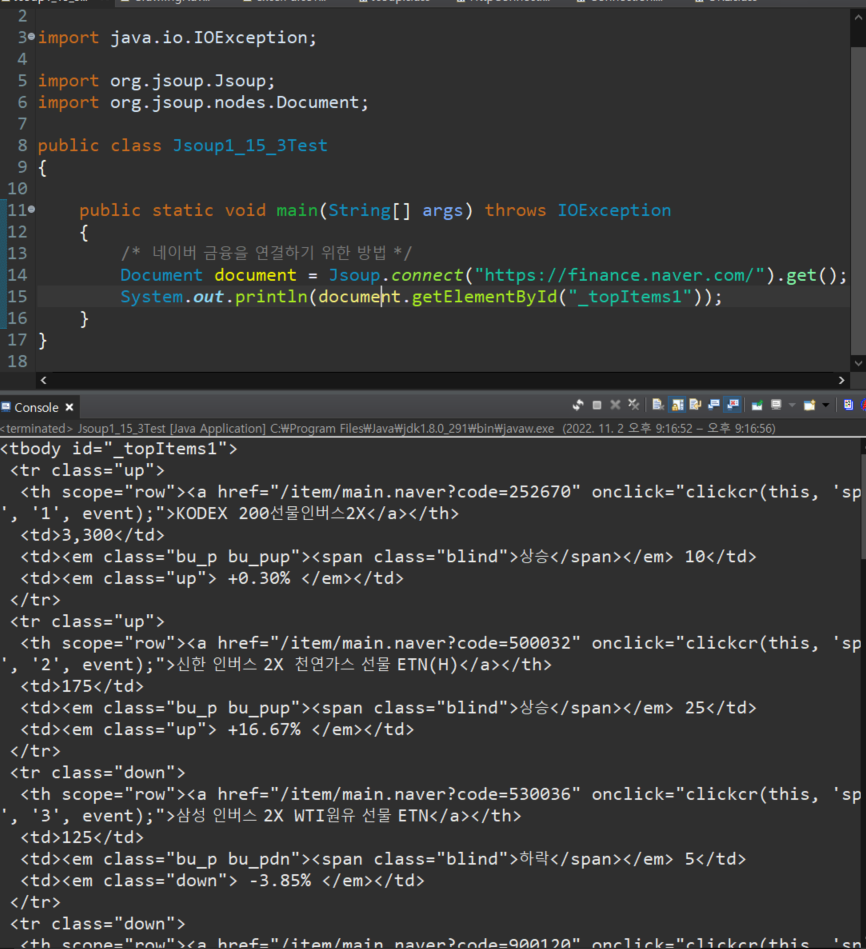
3. 아이디 이름을 #붙여서 썼을 때
document.select("#_topItems1")
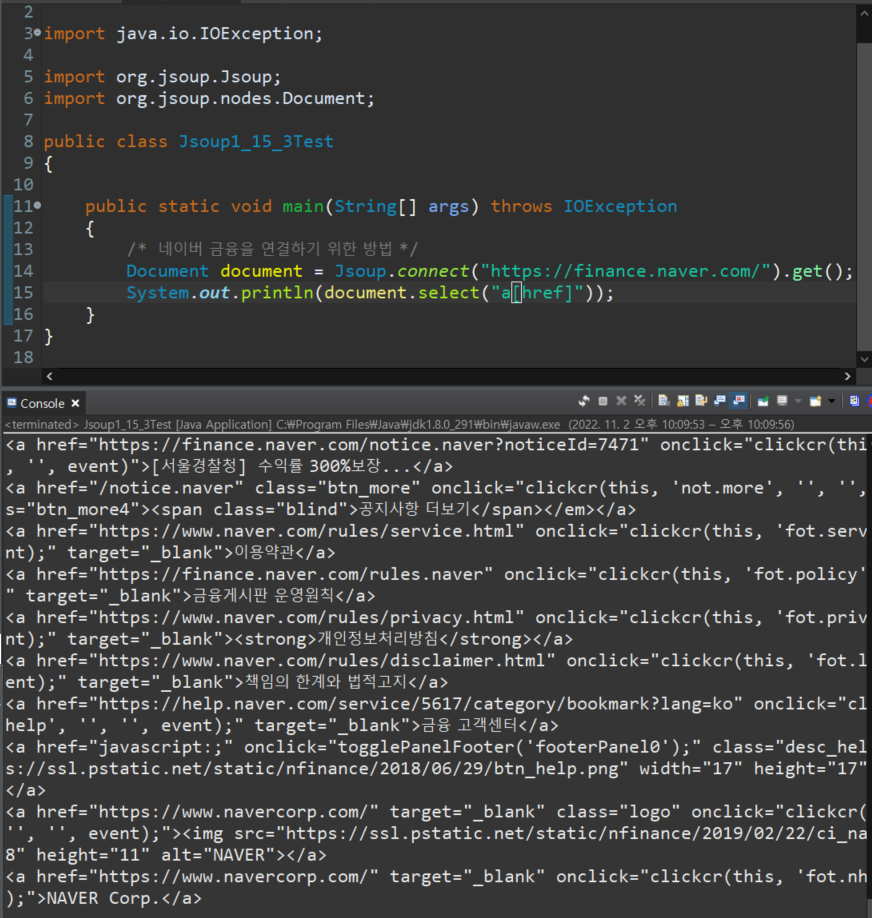
4. 태그와 해당 attribute를 조건주어 검색할 때
document.select("a[href]")
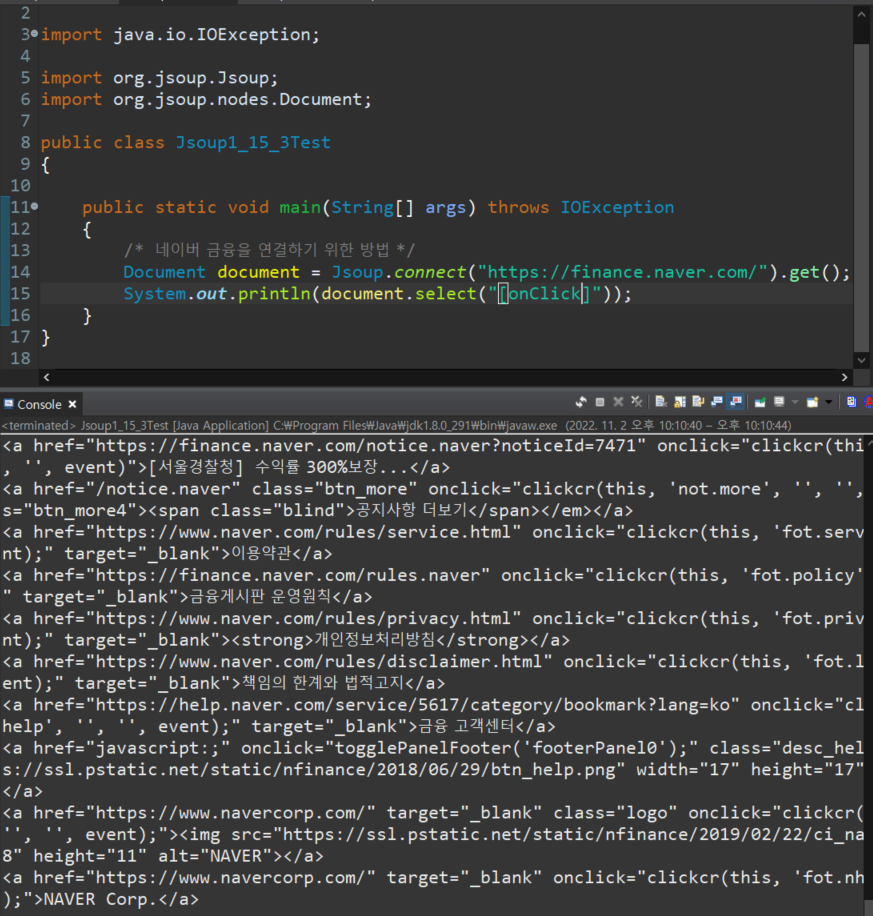
5. attribute 값만 검색할때
document.select("[onClick]")
정말 슈퍼 강력하지 않나요??? 제가 봤을땐 경이롭습니다.
그리고 심지어 자기네들도
Find elements that match the {@link Selector} CSS query, with this element as the starting context. Matched elements
* may include this element, or any of its children.
* <p>This method is generally more powerful to use than the DOM-type {@code getElementBy*} methods, because
* multiple filters can be combined, e.g.:</p>
* <ul>
* <li>{@code el.select("a[href]")} - finds links ({@code a} tags with {@code href} attributes)
* <li>{@code el.select("a[href*=example.com]")} - finds links pointing to example.com (loosely)
* </ul>
* <p>See the query syntax documentation in {@link org.jsoup.select.Selector}.</p>
* <p>Also known as {@code querySelectorAll()} in the Web DOM.</p>
설명으로 친절하게 알려주고 있고, getElementBy절보다 훨씬 강력하다고 설명하고 있답니다.
마치며...
이렇게 우리는 Jsoup 라이브러리를 간다하게 맛보기 정도로 3가지 방법에 대해 알아 보았습니다.
좀더 Deep 하게들어가면 파일을 읽고, HttpConnection 막 연결도하고 쿠키값도, 그리고 기존 HTML 소스도 변경하고 또 그걸 또 연결하고 html 파일 가져와서 열수도있고 ,,,
등등 수 많은 기능들이 있지만 우리가 원하는 기본 크롤링 기능에 대해서 저와 같이 코딩을 처음 접하고
적은 지식의 코더 희망꾼들에게 맞춤의 내용이지 않을까 싶어서 선별했습니다.
도움이 되었다면 많이 사용해주시고 틀린부분이나 부족한 부분이있다면 댓글달아주시면 바로바로 사과말씀과 수정하겠습니다.
지금까지 긴글 읽어 주셔서 감사합니다.
다음 포스팅은 엑셀관련된 라이브러리와 아까 이미지 파일에 대해서 다운로드 받는 방법에 대해서 알려드리겠습니다.





















댓글