
사이킷 런
파이썬에서 사용할 수 있는 머신러닝 라이브러리 중 하나로, 간결하고 효과적인 도구를 제공하여 머신러닝 모델을 구축하고 분석하는 데 사용된다.
장점
| 일관된 인터페이스 | 간단하고 일관된 API를 제공하여 여러 머신러닝 알고리즘을 쉽게 사용할 수 있게 한다. 덕분에 모델 간 전환 및 비교가 용이 |
| 다양한 머신러닝 알고리즘 | 사이킷런은 다양한 머신러닝 알고리즘을 포함하고있다. 지도학습, 비지도학습, 클러스터링, 차원축소, 등 다양한 작업을 수행할 수 있는 알고리즘들이 구현되어있다. |
| 데이터 전처리 도구 | 데이터를 전처리하고 정제하는 데 사용할 수 있는 다양한 도구와 함수를 제공하며 데이터의 스케일 조정, 특징 추출, 결측치 처리 등을 수행할 수 있다. |
| 효율적인 모델 평가 도구 | 모델의 성능을 측정하고 평가하기 위한 다양한 지표와 도구를 제공한다.. 교차 검증, 그리드 서치와 같은 기능을 통해 모델을 튜닝하고 최적의 하이퍼파라미터를 찾을 수 있다. |
| 온라인 문서와 예제 | 풍부한 온라인 문서와 예제를 제공하여 사용자가 라이브러리를 학습하고 적용가능하다. |
| 확장성 및 개방성 | 다양한 다른 라이브러리와 통합이 쉽도록 설계되어 있다. 다른 라이브러리와 함께 사용하여 머신러닝 파이프라인을 구축가능 |
라이브러리
- 선형 회귀분석
- 로지스틱 회귀분석
- KNN
- 나이브 베이즈
- 의사결정 트리
- 서포트 벡터머신
- 랜덤 포레스트
사이킷 런의 머신러닝 적용 알고리즘
1. 선형 회귀 분석
선형회귀분석이란?
선형 회귀는 종속 변수(또는 응답 변수)와 하나 이상의 독립 변수(또는 설명 변수) 간의 관계를 모델링하는 통계 기법 중 하나입니다.
주로 데이터의 경향을 설명하고 예측하는 데 사용됩니다.
선형 회귀의 기본 아이디어는 독립 변수들과 종속 변수 간의 선형 관계를 나타내는 최적의 선을 찾는 것입니다.
간단한 선형 회귀의 경우, y=mx+b 의 그래프와 유사하게 그려지며 점들이 이 그래프 주위를 맴도는 형식입니다.
라이브러리
from sklearn.linear_model import LinearRegression파이썬예제
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
# 예제 데이터 생성
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) # 독립 변수 (시간)
y = np.array([2, 4, 5, 4, 5]) # 종속 변수 (가격)
# 선형 회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X, y)
# 예측
y_pred = model.predict(X)
# 시각화
plt.scatter(X, y, color='black')
plt.plot(X, y_pred, color='blue', linewidth=3)
plt.xlabel('시간')
plt.ylabel('가격')
plt.show()결과

이번엔 좀더 많은 데이터로 훈련을 시켜보겠습니다. 약 3배에 달하도록 했습니다.
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
# 예제 데이터 생성
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) # 독립 변수 (시간)
y = np.array([2, 4, 5, 4, 5]) # 종속 변수 (가격)
# 더 많은 데이터 포인트 추가 (3배)
X_more = np.arange(6, 21).reshape(-1, 1)
y_more = 3 * X_more.flatten()
# 기존 데이터와 새로운 데이터 합치기
X_combined = np.concatenate((X, X_more), axis=0)
y_combined = np.concatenate((y, y_more), axis=0)
# 선형 회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X_combined, y_combined)
# 예측
y_pred_combined = model.predict(X_combined)
# 시각화
plt.scatter(X_combined, y_combined, color='black', label='DP')
plt.plot(X_combined, y_pred_combined, color='blue', linewidth=3, label='LR')
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.show()결과
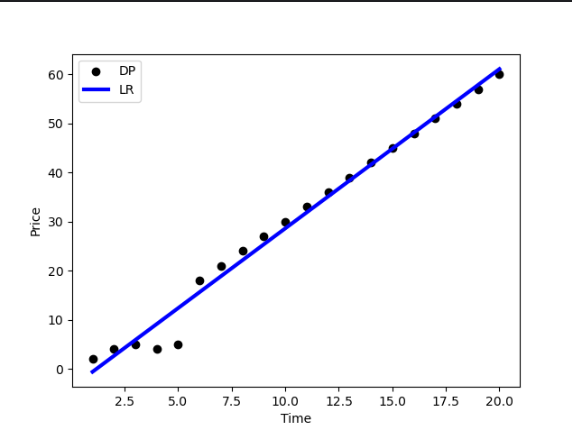
실데이터셋을 이용
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
data=load_iris()
x=data.data
y=data.target
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.8,test_size=0.2)
tmp=LinearRegression()
tmp.fit(x_train,y_train)
pre=tmp.predict(x_test)
print(pre)
print(y_test)데이터셋의 아이리스를 통해 간단하게 데이터 모델링을 학습을하고 모델에 대해서 예측을 해보는 소스이다.

2. 로지스틱 회귀분석
로지스틱회귀분석이란?
로지스틱 회귀는 종속 변수가 이진(binary)인 경우, 즉 두 개의 클래스 중 하나에 속하는 경우에 사용되는 통계 기법입니다.
로지스틱 회귀는 이름은 회귀지만 실제로는 분류 문제에 사용됩니다.
로지스틱 회귀는 선형 회귀와 유사하지만 종속 변수를 0과 1 사이의 값으로 변환하는 시그모이드 함수(로지스틱 함수)를 사용하여 작동합니다.
로지스틱 회귀를 머신러닝에 적용하기 위해서는 데이터를 이용하여 모델을 학습시키고, 학습된 모델을 사용하여 새로운 데이터에 대한 예측을 수행합니다. 간단한 로지스틱 회귀의 예시 코드를 보여드리겠습니다. 여기서는 scikit-learn 라이브러리를 사용합니다.
라이브러리
from sklearn.linear_model import LogisticRegression파이썬예제
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 예제 데이터 생성
np.random.seed(42)
X = np.random.randn(100, 2) # 2차원 데이터
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 단순한 결정 경계 생성
# 데이터 시각화
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=y, palette='coolwarm')
plt.title('Data Visualization')
plt.show()
# 데이터 분할 (학습 데이터와 테스트 데이터)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 생성 및 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 학습된 모델로 예측
y_pred = model.predict(X_test)
# 정확도 출력
accuracy = accuracy_score(y_test, y_pred)
print(f'정확도: {accuracy}')
# 혼동 행렬 시각화
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion matrix')
plt.xlabel('Expect')
plt.ylabel('RealVal')
plt.show()
# 평가 지표 출력
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f'정확도: {accuracy:.2f}')
print(f'정밀도: {precision:.2f}')
print(f'재현율: {recall:.2f}')
print(f'F1 스코어: {f1:.2f}')우선 예제데이터를 평균이 0이고 표준 편차가 1인 표준 정규 분포로 무작위 값으로 도배된 행과 열로 이루어진 100쌍의 데이터로 생성했다. 그래야 X,Y좌표가 찍히기 떄문임!
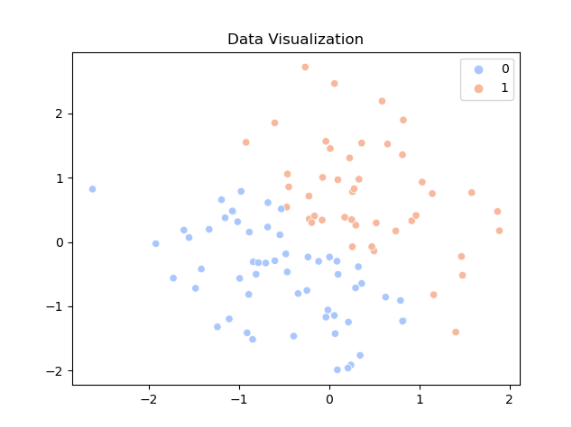
무작위로 찍히게 한다음 이 점들을 이용해서 좌표값 (X와 Y를 더함) 을 1과 0으로 분류한다.
그리고 데이터 학습을 통해서 생성한뒤 학습된 모델로 예측후 혼동행열을 시각화 하였다.
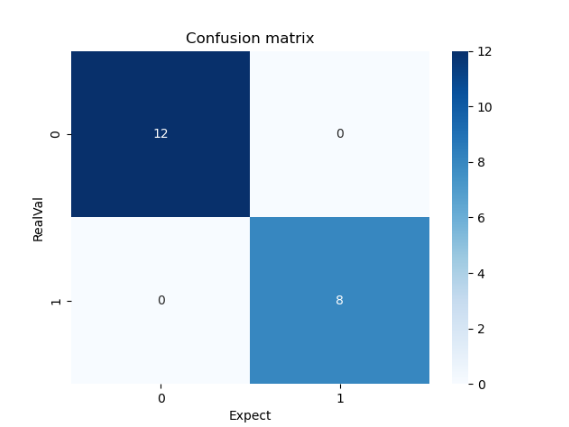
그리고 최종적으로 혼동 행열을 결과치를 통해 결과를 얻을 수 있다.

실데이터 예제
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
data=load_iris()
x=data.data
y=data.target
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.8,test_size=0.2)
tmp=LogisticRegression(solver='liblinear')
tmp.fit(x_train,y_train)
pre=tmp.predict(x_test)
print(pre)
print(y_test)
예측한값과 정답이 거의 일치하는 것을 알 수 있다.
3. KNN
KNN ( K-최근접 이웃) 이란?
K-Nearest Neighbors (KNN)은 지도 학습의 분류(Classification)와 회귀(Regression) 문제에 활용되는 간단하면서도 효과적인 알고리즘입니다.
KNN은 데이터 간의 거리를 기반으로 작동하며, 주어진 데이터 포인트의 주변에 위치한 k개의 가장 가까운 이웃들을 사용하여 예측을 수행합니다.
K-Nearest Neighbors (KNN)은 지도 학습의 분류(Classification)와 회귀(Regression) 문제에 활용되는 간단하면서도 효과적인 알고리즘입니다.
KNN은 데이터 간의 거리를 기반으로 작동하며, 주어진 데이터 포인트의 주변에 위치한 k개의 가장 가까운 이웃들을 사용하여 예측을 수행합니다.
KNN의 주요 특징:
- 거리 측정: KNN은 일반적으로 유클리디안 거리(Euclidean Distance)를 사용하여 데이터 포인트 간의 거리를 계산합니다. 다른 거리 측정 방법도 사용 가능합니다.
- 이웃의 개수(k): 모델 성능에 큰 영향을 미치는 하이퍼파라미터로, 예측할 때 참고하는 이웃의 개수를 의미합니다.
- 데이터 분포에 민감: KNN은 주변 이웃의 정보를 활용하므로 데이터가 밀집된 지역에서 잘 작동하나, 특히 차원이 높은 데이터에서는 성능이 저하될 수 있습니다.
KNN의 적용:
- 분류 (Classification): KNN은 클래스가 뚜렷한 분류 문제에서 잘 작동합니다. 예를 들어, 데이터 포인트의 주위에 같은 클래스의 이웃이 많다면 해당 데이터 포인트도 해당 클래스로 예측됩니다.
- 회귀 (Regression): KNN은 회귀 문제에도 적용될 수 있습니다. 예측할 데이터 포인트와 가장 가까운 이웃들의 평균이나 중간값을 사용하여 연속적인 값 예측이 가능합니다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import numpy as np
# 예제 데이터 생성
np.random.seed(42)
X = np.random.randn(100, 2) # 2차원 데이터
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 단순한 결정 경계 생성
# 데이터 시각화 (영어 라벨 사용)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm')
plt.title('Data Visualization')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# 데이터 분할 (학습 데이터와 테스트 데이터)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# KNN 모델 생성 및 학습 (이웃의 개수 k=3으로 설정)
knn_model = KNeighborsClassifier(n_neighbors=3)
knn_model.fit(X_train, y_train)
# 테스트 데이터에 대한 예측
y_pred = knn_model.predict(X_test)
# 정확도 출력
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')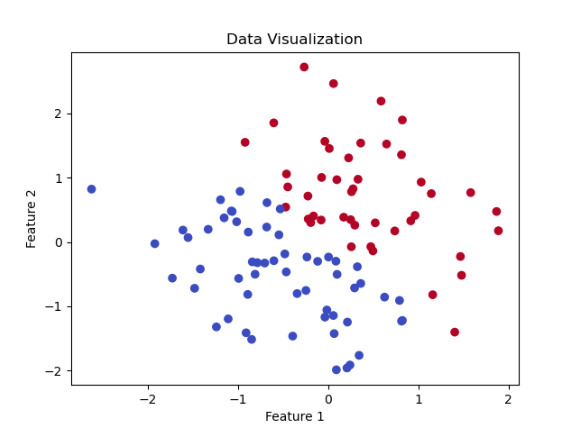
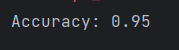
이때 정확도가 나오게된다.
여기서 테스트데이터를 약 3배정도 늘린뒤 돌려보곘습니다.
#기존의 test_size 를 0.2에서 0.6으로 올려보겠습니다.
#X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.6, random_state=42)
얼추 정확도가 0.02더 증가한 모습을 볼 수 있습니다.
실데이터예제
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
data=load_iris()
x=data.data
y=data.target
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.8,test_size=0.2)
tmp=KNeighborsClassifier(n_neighbors=2)
tmp.fit(x_train,y_train)
pre=tmp.predict(x_test)
print(pre)
print(y_test)모델링을 할때 분류할 이웃을 찾을때 몇개나 찾을거냐 할때 2개를 지정해주었다.

여기까지 싸이킷런의 유용한 라이브러리 7개중3개를 알아보았습니다. 다음 포스팅에서는
나머지 4개에 대해서 알아보겠습니다.
'인공지능 > 머신러닝' 카테고리의 다른 글
| 8. 데이터 결측치 시각화 - 데이터 결측치 시각화 (0) | 2023.09.25 |
|---|---|
| 6. 딥러닝을 위한 프레임 워크 - 파이토치(PyTorch) (0) | 2023.09.19 |
| 5. 데이터 시각화를 위한 matplotlib (0) | 2023.09.19 |
| 3. 머신러닝을 위한 판다스(Pandas) (0) | 2023.09.05 |
| 2. 머신러닝을 위한 넘파이(NumPy) (0) | 2023.09.05 |




댓글