
예전부터 머신러닝에 대해서 깔짝 공부를 하다 보니 익숙해진 패키지중 하나가 판다스입니다.
복습차원으로 간단하게 기록형으로 작성하고
나중에 제가 다시 딥러닝을 공부하게 되면 슬쩍보고 바로 이해가 빡!
될수 있도록 작성했습니다.
0. 판다스란?
파이썬 프로그래밍 언어를 기반으로한 데이터 조작 및 분석을 위한 라이브러리입니다.
주로 데이터프레임(DataFrame)이라는 자료구조를 사용하여 데이터를 다루며,
데이터를 읽고 쓰는데 편리한 기능들을 제공합니다.
이를 통해 데이터 전처리, 분석, 시각화 등의 작업을 보다 쉽게 할 수 있습니다.
1. 설치
pip install pandas2. 판다스 사용
1) 시리즈
import pandas as pd
sr = pd.Series([17000
,18000
,1000
,5000]
,index=["pizza"
,'chikhen'
,'coke'
,'beer'])
print(sr)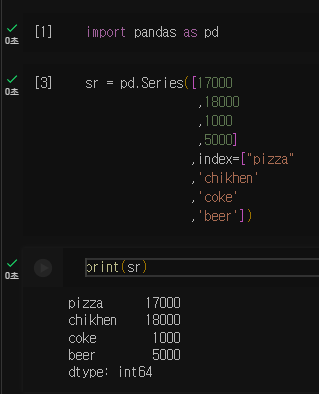
시리즈 클래스는 1차원 배열의 값에 각 값에 대앙되는 인덱스를 부여할 수 있는 구조를 가지고 있음
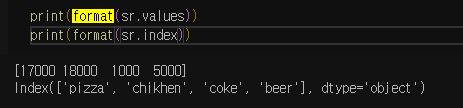
값과 인덱스를 출력가능
2) 데이터 프레임
데이터 프레임은 2차원 리스트를 매개변수로 전달한다. 2차원이므로 양방향 인덱스와 열방향인덱스
즉 오와 열이 있는 자료구조이다. 시리즈에 열을 붙인 것이라고 생각하면 편하다.
val = [[1,2,3]
,[4,5,6]
,[7,8,9]]
idx = ['one'
,'two'
,'three']
col = ['A','B','C']
df = pd.DataFrame(val, index=idx , columns=col)
print(df)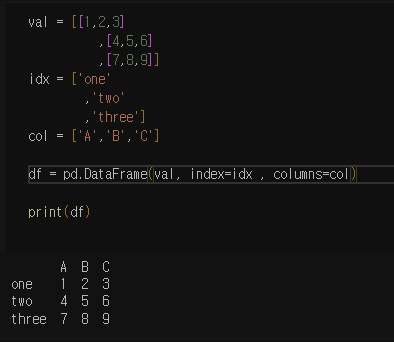
인덱스와 값에 열을 추가한 세 개의 구성요소로 부터 데이터 프레임을 출력

3. 데이터 프레임 생성 방법
데이터 프레임은 리스트, 시지르, 딕셔너리, 넘파이의 ndarrays, 또 다른 데이터 프레임 으로 생성가능
- 리스트로 생성
data = [
['1000','kim',99]
,['1001','lee',78]
,['1002','park',94]
,['1003','hwang',88]
,['1004','jung',90]
,['1005','oh',98]
,['1006','choi',80]
]
df= pd.DataFrame(data)
print(df)
- 딕셔너리를 통해 데이터프레임 생성 (딕셔너리는 Map과 비슷하다)
data = {
'학 번' : ['1000', '1001', '1002', '1003', '1004', '1005'],
'이 름' : [ 'lee', 'park', 'kim', 'hwang', 'oh', 'choi'],
'점 수': [90.72, 78.09, 98.43, 64.19, 81.30, 99.14]
}
df = pd.DataFrame(data)
print(df)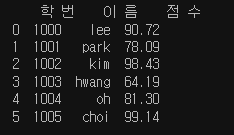
4. 데이터 프레임 조회 함수
- head(n) - 앞 부분 n개만 보기
- tail(n) - 뒷 부분을 n개만 보기
- df['열이름'] - 해당되는 열을 확인

2. 외부 데이터 읽기
Pandas는 CSV, 텍스트, 엑셀, JSON 등 다양한 데이터 파일을 읽고 데이터 프레임을 생성가능하다.
과거에 혼자 학습하던 자료가있어서 예제로 사용해보겠다.
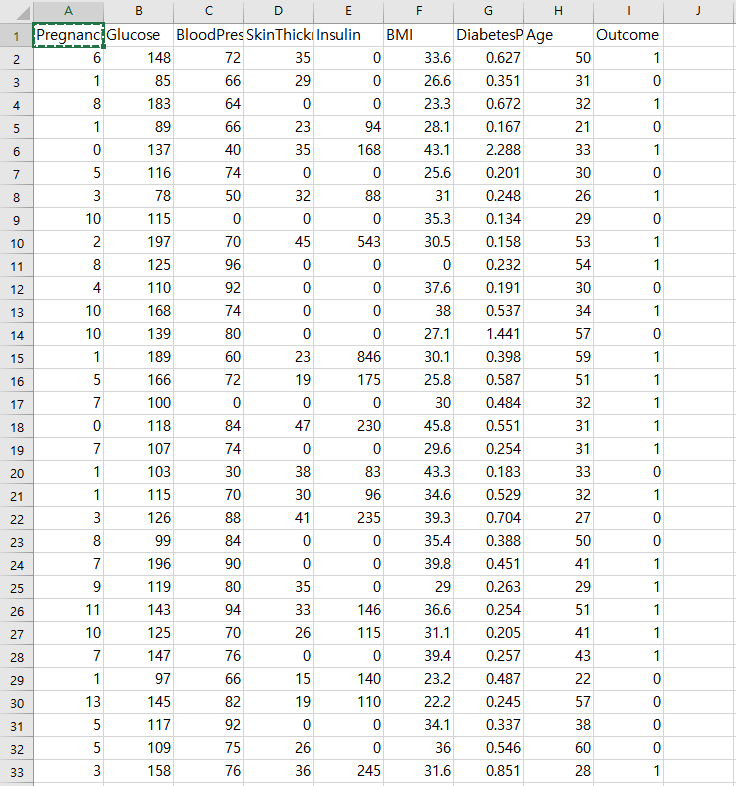
df = pd.read_csv('../diabetes.csv')
print(df)
df = pd.read_csv('../diabetes.csv')
#행과 열의 개수를 튜플형태로 반환한다.
print('--shape--')
print(df.shape)
#각 열에 대한 기술통계량 제공 , 중앙값, 평균, 최소값, 최대값 등등나온다.
print('---df.describe()---')
print(df.describe())
#누락된 값이 있는 행을 제거
print('--df.dropna()--')
print(df.dropna())
#각 항목이 누락되었는지 확인 누락이면 true, 아니면 false
print('--df.isNull()--')
print(df.isnull())
--shape--
(768, 9)
---df.describe()---
Pregnancies Glucose BloodPressure SkinThickness Insulin \
count 768.000000 768.000000 768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 20.536458 79.799479
std 3.369578 31.972618 19.355807 15.952218 115.244002
min 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000
50% 3.000000 117.000000 72.000000 23.000000 30.500000
75% 6.000000 140.250000 80.000000 32.000000 127.250000
max 17.000000 199.000000 122.000000 99.000000 846.000000
BMI DiabetesPedigreeFunction Age Outcome
count 768.000000 768.000000 768.000000 768.000000
mean 31.992578 0.471876 33.240885 0.348958
std 7.884160 0.331329 11.760232 0.476951
min 0.000000 0.078000 21.000000 0.000000
25% 27.300000 0.243750 24.000000 0.000000
50% 32.000000 0.372500 29.000000 0.000000
75% 36.600000 0.626250 41.000000 1.000000
max 67.100000 2.420000 81.000000 1.000000
--df.dropna()--
Pregnancies Glucose BloodPressure SkinThickness Insulin BMI \
0 6 148 72 35 0 33.6
1 1 85 66 29 0 26.6
2 8 183 64 0 0 23.3
3 1 89 66 23 94 28.1
4 0 137 40 35 168 43.1
.. ... ... ... ... ... ...
763 10 101 76 48 180 32.9
764 2 122 70 27 0 36.8
765 5 121 72 23 112 26.2
766 1 126 60 0 0 30.1
767 1 93 70 31 0 30.4
DiabetesPedigreeFunction Age Outcome
0 0.627 50 1
1 0.351 31 0
2 0.672 32 1
3 0.167 21 0
4 2.288 33 1
.. ... ... ...
763 0.171 63 0
764 0.340 27 0
765 0.245 30 0
766 0.349 47 1
767 0.315 23 0
[768 rows x 9 columns]
--df.isNull()--
Pregnancies Glucose BloodPressure SkinThickness Insulin BMI \
0 False False False False False False
1 False False False False False False
2 False False False False False False
3 False False False False False False
4 False False False False False False
.. ... ... ... ... ... ...
763 False False False False False False
764 False False False False False False
765 False False False False False False
766 False False False False False False
767 False False False False False False
DiabetesPedigreeFunction Age Outcome
0 False False False
1 False False False
2 False False False
3 False False False
4 False False False
.. ... ... ...
763 False False False
764 False False False
765 False False False
766 False False False
767 False False False이것으로 간단하게 복습겸 판다스의 기본문법에 대해 학습했다. 나중에 잊더라도 한번 스윽! 보면
기억날정도까지 학습했다.
너무깊게 들어가고 너무 많은 함수를 알기보다 우선 이정도 까지 알고 나중에 필요하거나 그럴때
채찍피티나 인터넷검색을 통해 차근차근 습득해 나가는 것도 시간대비 효율이 좋을 것 같아 그렇게 학습하고 넘어가겠다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 1. 딥 러닝 공부를 시작하면서.. (0) | 2024.03.21 |
|---|

댓글