
1. LLM의 개념
LLM (Large Language Model)**은 대규모 데이터셋을 기반으로 학습하여 자연어를 이해하고 생성할 수 있는 심층 신경망 기반 AI 모델입니다. Transformer 아키텍처를 활용하여 텍스트 데이터의 문맥을 파악하고, 문장 생성, 기계 번역, 요약, 질의응답(QA) 등의 자연어 처리(NLP) 작업을 수행합니다.
이 모델은 기본적으로 확률적 언어 모델링(Probabilistic Language Modeling)에 기반하며, 특정 단어 또는 문장의 출현 확률을 예측하는 방식으로 작동합니다.
대표적인 LLM으로는 GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), T5 (Text-to-Text Transfer Transformer) 등이 있으며, 최근에는 Multi-Modal LLM이 등장하면서 이미지, 영상, 코드 등 텍스트 외의 데이터도 학습하는 방향으로 발전하고 있습니다.
1-1. 트랜스포머를 이용한 모델
LLM은 기본적으로 여러 가지 언어 모델 프레임워크(LLM Framework) 내에서 동작하며, 각 프레임워크는 자체적인 아키텍처(Architecture) 및 학습 방법론을 기반으로 여러 세부 모델을 포함하고 있습니다.
(1) GPT (Generative Pre-trained Transformer)
Transformer 기반의 Autoregressive 모델로, 주어진 문맥에서 다음 토큰을 예측하는 방식으로 작동합니다.
P(w_t | w_{t-1}, ..., w_1) 형태의 확률 분포를 기반으로 문장을 생성하며, 생성된 단어를 다시 입력으로 받아 반복적으로 문장을 확장합니다.
① 기본 개념
GPT는 Transformer의 Decoder 아키텍처만 사용하며, 순차적 생성(Auto-Regressive Decoding) 방식으로 작동합니다.
이를 통해 문맥을 이해하고 새로운 문장을 생성하는 데 강점을 보이며, Zero-shot, Few-shot, Fine-tuning을 통한 다양한 활용이 가능합니다.
② 확률 모델 수식
GPT는 자연어 문장을 확률적 생성 과정으로 모델링합니다.
즉, 주어진 문장에서 다음 단어 wtw_t 가 등장할 확률을 이전 단어들의 문맥을 고려하여 예측하는 방식입니다.
GPT의 목표는 전체 문장 P(w1,w2,...,wn)P(w_1, w_2, ..., w_n) 의 확률을 최대화하는 것입니다.
이를 위해 조건부 확률(Conditional Probability) 개념을 활용하여 다음과 같이 표현할 수 있습니다.
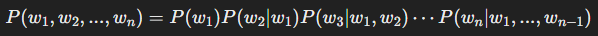
이 식을 일반화하면, GPT의 확률 모델은 다음과 같이 표현됩니다.
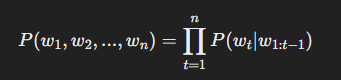
즉, 각 단어 는 이전 단어들의 확률 분포에 의해 결정됩니다.
이러한 방식은 Markov Assumption(마르코프 가정) 에 기반하여, 문맥(Context) 정보가 모델 내부에서 확률적으로 처리될 수 있도록 합니다.
2. 확률 모델 유도 과정
(1) 조건부 확률과 체인 룰 (Chain Rule)
자연어 문장은 단어들의 시퀀스(sequence)로 구성되며, 각 단어는 이전 단어들에 의존하는 확률 분포를 따릅니다.
이 개념을 확률 이론에서 체인 룰 (Chain Rule of Probability) 을 이용하여 설명할 수 있습니다.
체인 룰의 기본 형태는 다음과 같습니다.
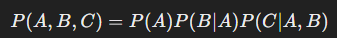
이를 일반적인 단어 시퀀스에 적용하면,
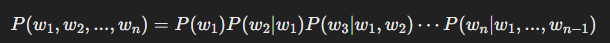
즉, 각 단어는 앞의 단어들이 주어진 상태에서 조건부 확률을 가진다는 개념이 됩니다.
(2) 마르코프 가정 (Markov Assumption)
GPT는 Transformer 기반 모델이지만, 확률적 표현 방식에서 마르코프 과정(Markov Process) 의 개념을 적용할 수 있습니다.
마르코프 가정이란, 미래 상태(=다음 단어)는 현재 상태에만 의존하고, 과거의 모든 정보를 기억할 필요가 없다는 가정입니다.
이 가정을 적용하면, 위에서 도출한 확률 모델에서 이전 모든 단어가 아닌, 특정 개수의 이전 단어만 참고하여 확률을 계산할 수 있습니다.

하지만, Transformer 기반의 GPT는 이전 문맥 전체를 사용하여 학습하기 때문에, 일반적인 N-gram 모델과 달리 긴 문맥을 고려할 수 있습니다.
(3) 확률 분포 모델링
GPT는 각 단어 wtw_t 의 조건부 확률을 예측하기 위해 신경망을 사용하여 확률 분포를 직접 모델링합니다.
즉, 모델이 학습한 가중치 θ\theta 를 이용하여 확률 분포를 다음과 같이 정의합니다.

여기서
- Function0 는 GPT의 Transformer 모델
- softmax 함수를 이용하여 확률값을 출력
즉, GPT는 이전 문맥을 입력으로 받아, 다음 단어의 확률 분포를 예측하는 모델로 볼 수 있습니다.
3. 확률 모델을 통한 결과 예측 (Inference)
GPT는 학습이 완료된 후, 다음과 같은 과정으로 텍스트를 생성합니다.
- 초기 문장 입력
- 사용자가 “The cat sat” 라는 문장을 입력했다고 가정합니다.
- 다음 단어 예측
- 모델이 이전 단어들의 문맥을 고려하여 다음 단어 wtw_t 의 확률 분포를 예측합니다.
- 예를 들어, “on” 이 0.8의 확률, “under” 가 0.1의 확률을 가진다고 가정하면, “on”이 선택될 가능성이 큽니다.
- 단어 생성 및 반복
- “on”을 선택한 후, 다시 모델에 넣고 다음 단어를 예측합니다.
- 이러한 과정을 반복하여 문장을 완성합니다.
즉, 각 단어는 이전 단어들의 확률적 관계에 의해 선택되며, 문장이 자연스럽게 확장됩니다.
4. 결론 및 추론
이제 GPT의 확률 모델을 바탕으로 몇 가지 중요한 결론을 유추할 수 있습니다.
- GPT는 시퀀스 데이터를 확률적 모델로 해석하여 단어를 생성한다.
- 각 단어는 이전 문맥의 확률적 관계를 기반으로 선택되며, 조건부 확률(Conditional Probability) 개념을 따른다.
- Transformer 기반이므로 긴 문맥을 고려할 수 있으며, 일반적인 Markov 모델보다 강력한 문맥 학습이 가능하다.
- GPT의 최적화는 Softmax를 기반으로 확률 분포를 학습하는 과정이며, 이는 대규모 데이터와 강력한 연산을 요구한다.
- 완전히 새로운 문장을 생성할 수 있으며, 확률적으로 자연스러운 문장을 만들지만, 완벽한 의미론적 이해는 어렵다.
③ 대표적인 세부 모델
| GPT-2 | 1.5B | 최초의 공개된 대규모 GPT 모델, Fine-tuning 없이 다양한 작업 가능 |
| GPT-3 | 175B | Few-shot Learning을 통해 특정 작업 수행 가능 |
| GPT-4 | 미공개 (1T+ 추정) | 멀티모달 지원, 강화된 논리적 추론 성능 |
(2) BERT (Bidirectional Encoder Representations from Transformers)
GPT와 달리 Transformer의 Encoder 아키텍처를 기반으로 설계되었으며, 문맥을 양방향(Bidirectional) 으로 이해하는 것이 특징입니다.
① 기본 개념
- Masking 기법을 활용하여 학습 진행 (MLM, Masked Language Modeling)
- 특정 단어를 마스킹한 후 이를 복원하는 방식으로 문맥 이해 능력을 학습
- 문장 간 관계 예측(NSP, Next Sentence Prediction) 기능 포함
② 학습 방식 수식
BERT의 MLM 학습 과정은 다음과 같은 확률 모델을 따릅니다.
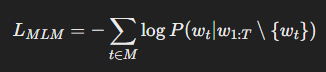
즉, 전체 문장에서 특정 토큰을 마스킹(M)하고, 이를 올바르게 예측하는 확률을 최대화하는 방식입니다.
③ 대표적인 세부 모델
| BERT-base | 110M | 기본적인 NLP 작업 수행 가능 |
| BERT-large | 340M | 성능 향상을 위해 더 많은 레이어 사용 |
| RoBERTa | 355M | BERT의 학습 방식을 개선하여 성능을 최적화 |
(3) T5 (Text-to-Text Transfer Transformer)
기존 NLP 작업을 모두 Text-to-Text 형식으로 변환하여 학습하는 접근 방식을 채택합니다.
① 기본 개념
- 입력과 출력을 모두 텍스트 포맷으로 통일하여 다양한 NLP 작업을 수행할 수 있도록 설계
- 학습 태스크를 Text-to-Text 변환을 기반으로 일반화
- GPT 및 BERT와 달리 Seq2Seq (Encoder-Decoder) 구조 사용
② 학습 방식 수식
T5는 일반적인 NLP 태스크를 다음과 같은 형태로 변환하여 학습합니다.
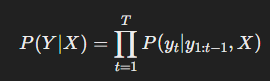
즉, 입력(X)과 출력(Y)을 Seq2Seq 방식으로 변환한 후, 조건부 확률을 최대화하는 방식입니다.
③ 대표적인 세부 모델
| T5-Small | 60M | 소규모 파라미터로 빠른 응답 가능 |
| T5-Base | 220M | 일반적인 NLP 작업 수행 |
| T5-Large | 770M | 고성능 태스크 수행 가능 |
(4) XLNet
BERT의 단점을 보완하기 위해 등장한 모델로, Permutation-based Language Modeling 방식을 채택합니다.
① 기본 개념
- GPT의 Autoregressive 특성과 BERT의 Bidirectional 특성을 결합
- Masking 대신 Permutation 방식을 활용하여 문맥 이해 능력 강화
- 기존 BERT 모델보다 문맥을 더 깊이 반영 가능
② 학습 방식 수식
XLNet은 BERT의 MLM 방식과 달리, 토큰 순서를 변형하여 학습하는 방식을 적용합니다.
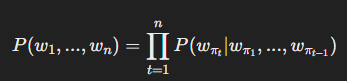
여기서 πt\pi_t는 랜덤한 순열을 의미하며, 순차적 학습을 피할 수 있습니다.
③ 대표적인 세부 모델
| XLNet-base | 110M | 일반적인 NLP 작업 수행 |
| XLNet-large | 340M | 문맥 이해 능력이 더 뛰어난 버전 |
(5) ALBERT (A Lite BERT)
BERT 모델을 경량화하여 더 적은 파라미터로 높은 성능을 유지하는 것이 특징입니다.
① 기본 개념
- Factorized Embedding Parameterization 기법을 적용하여 가중치 공유
- Sentence Order Prediction (SOP) 기법으로 문맥 이해 개선
- 기존 BERT 대비 연산량 감소, 메모리 효율성 증가
② 대표적인 세부 모델
| ALBERT-base | 12M | 빠른 연산 속도 |
| ALBERT-large | 18M | 성능과 속도 밸런스 |
| GPT (Generative Pre-trained Transformer) | 생성 능력에 특화, 미세 조정 없이도 강력한 성능 발휘 | GPT-2, GPT-3, GPT-4 |
| BERT (Bidirectional Encoder Representations from Transformers) | 문맥을 양방향으로 이해, NLP 태스크에 최적화 | BERT-base, BERT-large, RoBERTa |
| T5 (Text-to-Text Transfer Transformer) | 입력을 텍스트로 받아 출력도 텍스트로 반환하는 구조 | T5-Small, T5-Base, T5-Large |
| XLNet | BERT의 단점을 보완, 순차적 학습이 아닌 Permutation-based 학습 | XLNet-base, XLNet-large |
| ALBERT (A Lite BERT) | BERT의 경량화 모델, 더 적은 파라미터로 높은 성능 제공 | ALBERT-base, ALBERT-large |
2. 통계적 언어 모델 (Statistical Language Model, SLM)
2.1 개념 및 기본 원리
통계적 언어 모델은 확률적 방법론을 사용하여 텍스트 데이터를 학습하고, 다음 단어가 등장할 확률을 기반으로 문장을 생성하거나 분석합니다.
2.2 N-그램 모델
N-그램(N-gram) 모델은 통계적 언어 모델의 대표적인 기법으로, 단어의 조건부 확률을 단순화하는 방법입니다.
(1) N-그램 확률 수식
언어 모델에서 특정 단어 시퀀스의 확률은 다음과 같이 근사됩니다.

예를 들어, Bigram(2-gram) 모델은 현재 단어가 이전 단어 하나에만 의존한다고 가정합니다.

Trigram(3-gram) 모델은 현재 단어가 이전 두 단어에 의존합니다.

이처럼 N이 커질수록 문맥 정보를 더 많이 반영할 수 있지만, 데이터가 부족하면 확률값이 0이 되는 희소성(Sparsity) 문제가 발생할 수 있습니다.
2.3 확률적 스무딩(Smoothing)
데이터 희소성을 해결하기 위해 다양한 스무딩 기법이 사용됩니다.
라플라스 스무딩 (Laplace Smoothing)

백오프(Back-off)와 인터폴레이션(Interpolation)
낮은 N-그램의 확률을 보정하는 방법입니다.

여기서 λ1+λ2+λ3=이 되도록 조정합니다.
3. 신경망 언어 모델 (Neural Language Model, NLM)
3.1 개념 및 발전 배경
N-그램 기반 통계적 언어 모델은 강력하지만, 다음과 같은 한계가 있습니다.
- 긴 문맥(Context) 처리 불가능 → N이 증가하면 학습 데이터 부족으로 인해 성능 저하
- 단어 간 의미적 관계 미반영 → 같은 의미의 단어라도 다르게 처리됨
- 희소성 문제(Sparsity) → 미등록 단어(OOV, Out-of-Vocabulary) 처리 어려움
이를 해결하기 위해 **신경망 언어 모델(Neural Language Model, NLM)**이 등장하였습니다.
3.2 인공 신경망 기반 언어 모델
(1) 확률 모델 수식
기본적으로 신경망 언어 모델은 주어진 문맥 (w1,w2,...,wt−1)(w_1, w_2, ..., w_{t-1})에서 다음 단어 wtw_t의 확률을 예측하는 함수 fθf_{\theta}를 학습합니다.
P(wt∣w1,w2,...,wt−1)=fθ(w1,w2,...,wt−1)P(w_t | w_1, w_2, ..., w_{t-1}) = f_{\theta}(w_1, w_2, ..., w_{t-1})
이 함수는 주로 **신경망(Neural Networks)**을 사용하여 모델링됩니다.
(2) 주요 신경망 모델 아키텍처
(i) 피드포워드 신경망 언어 모델 (Feedforward Neural Network, FNN-LM)
- 입력: 단어의 One-hot Encoding
- 은닉층: Fully Connected Layer
- 출력층: Softmax 함수
하지만, 문맥의 길이가 제한되며, 긴 문장에서 의미를 반영하기 어렵습니다.
(ii) 순환 신경망 (Recurrent Neural Network, RNN)
- 시간 축을 따라 이전 상태(hidden state)를 전달하여 문맥을 반영
- 하지만 기울기 소실(Vanishing Gradient) 문제 발생
(iii) LSTM/GRU 기반 모델
- 장기 의존성(Long-Term Dependency) 문제 해결
- 셀 상태(Cell State)와 게이트(Gate) 구조 활용
통계적 언어 모델 vs 신경망 언어 모델 비교
| 문맥 고려 범위 | 짧음 (N-그램 범위) | 길고 유연함 |
| 희소성 문제 | 있음 (OOV 문제) | 단어 임베딩으로 해결 |
| 일반화 성능 | 낮음 | 높음 |
| 계산량 | 상대적으로 적음 | 많음 (GPU 필요) |
| 주요 모델 | N-그램, HMM | RNN, LSTM, Transformer |
댓글