
LLM(Large Language Model)의 생성 과정은 단순한 모델 훈련이 아니라, 데이터 수집 → 모델 설계 → 학습 → 평가 및 검증 → 배포 및 유지보수라는 복잡한 절차를 거칩니다.
각 과정에서 고려해야 할 핵심 요소와 이를 설명하겠습니다.
데이터 수집
① 데이터 출처
LLM의 성능은 학습 데이터의 품질에 따라 좌우됩니다.
일반적으로 다음과 같은 데이터 출처를 활용합니다.
- 웹 문서: Wikipedia, 뉴스 기사, 블로그, 논문 등
- 책 및 논문: 학술 문헌, eBook
- 소셜 미디어: Twitter, Reddit, Quora 등
- 코드 리포지토리: GitHub, Stack Overflow 등
이 데이터를 수집한 후 데이터 정제(Data Cleaning) 과정을 거칩니다.
② 데이터 정제
원본 데이터는 중복, 오탈자, 의미 없는 기호 등이 포함되어 있어 모델 학습에 적합하지 않습니다.
따라서, 텍스트 정제와 필터링이 필요합니다.
(1) 데이터 전처리
- HTML 태그 제거
- 특수 문자, 이모지 제거
- 중복 데이터 필터링
- 문법적 오류 수정
(2) 데이터 필터링
- 유해 콘텐츠 제거 (NSFW, Hate Speech)
- 광고성 텍스트 제거
- 불완전한 문장 제거
이 과정에서 흔히 사용하는 텍스트 정규화(Normalization) 기법은 아래와 같습니다.
- 소문자 변환: "Hello" → "hello"
- 불용어(Stopword) 제거: "I am going to the park" → "going park"
- 어간 추출(Stemming) & 표제어 추출(Lemmatization)
- "running" → "run"
- "better" → "good"
이후, 데이터는 라벨링(Labeling) 과정을 거쳐 특정 NLP 태스크를 수행할 수 있도록 가공됩니다.
모델 설계
LLM의 성능을 결정하는 요소는 모델 구조, 파라미터 수, 학습 방법입니다.
① Transformer 아키텍처
LLM의 기반이 되는 Transformer 모델은 Attention 메커니즘을 활용하여 문맥을 학습합니다.
이를 수식적으로 표현하면 다음과 같습니다.
Self-Attention 수식

- QQ : Query 행렬
- KK : Key 행렬
- VV : Value 행렬
- dkd_k : 차원 크기 정규화
이 수식은 각 단어(토큰)의 중요도를 계산하여 문맥을 이해하는 데 사용됩니다.
② 토큰화(Tokenization)
LLM은 단순히 문장을 그대로 학습하는 것이 아니라, 문장을 토큰(Token) 단위로 나눠서 학습합니다.
이 과정에서 다양한 토크나이제이션 기법이 사용됩니다.
(1) WordPiece (BERT 사용)
- "unhappiness" → ["un", "##happiness"]
(2) BPE (Byte Pair Encoding, GPT 사용)
- "low", "lowest", "lower" → ["low", "est", "er"]
이러한 방식으로 문장을 압축적으로 표현하고, 모델이 더 효과적으로 학습할 수 있도록 합니다.
모델 학습
모델 학습은 크게 사전 학습(Pretraining), 미세 조정(Fine-tuning), 강화 학습(RLHF) 단계로 나뉩니다.
모델링은 입력 데이터에서 패턴을 찾아 학습하고, 이를 일반화하여 새로운 데이터에 적용하는 과정입니다.
우리가 데이터를 보면 특정 규칙을 파악할 수 있는데, 이 규칙을 수학적으로 표현한 것이 모델입니다.
예제 1️⃣: 고양이 사진을 인식하는 모델
- 입력(Training Data):
- 다양한 고양이 사진을 수집
- 다양한 강아지 사진도 함께 수집하여 차이를 구분하도록 학습
- 특징(Feature) 추출:
- "고양이는 보통 귀가 뾰족하다."
- "고양이의 눈 모양이 특정 패턴을 가진다."
- "고양이는 수염이 길다."
- 패턴 학습:
- 모델이 고양이의 특징을 찾아 학습
- 새로운 사진이 들어오면 학습된 패턴을 활용해 고양이인지 판단
🔹 LLM도 동일한 원리!
- 문장에서 단어가 등장하는 패턴을 학습
- "나는 밥을 먹었다."와 "나는 학교에 갔다."를 보면 "나는" 뒤에는 동사가 등장한다는 규칙을 학습
- 이를 바탕으로 "나는 ..." 다음에 올 단어를 예측
① 사전 학습(Pretraining)
사전 학습 단계에서 LLM은 자가회귀 모델(Auto-Regressive Model) 이나 마스크드 언어 모델(Masked LM) 방식을 사용합니다.
사전 학습은 모델이 일반적인 패턴과 언어 구조를 학습하는 과정입니다.
고양이 예제를 활용해 설명하겠습니다.
📌 고양이 이미지 분류에서 사전 학습
- 다양한 고양이 사진을 학습하여 "고양이"라는 개념을 이해
- 강아지, 고양이, 사자, 호랑이 등의 사진을 함께 학습하며 차이점을 학습
🔹 LLM의 사전 학습
- "나는 오늘 맛있는 밥을 먹었다."
- "나는 학교에서 공부를 했다."
- "나는 친구와 영화를 봤다."
- "나는" 다음에 나오는 단어들의 패턴을 학습
- 이를 바탕으로 다음 단어를 예측
자가회귀 모델 (Auto-Regressive Model)
LLM은 다음 단어를 예측하는 방식으로 학습됩니다.

즉, 이전 단어들의 확률을 곱하여 전체 문장의 확률을 계산합니다.
예제 문장: "나는 오늘 맛있는 밥을 먹었다."
- P(나는)P(\text{나는})
- P(오늘∣나는)P(\text{오늘} \mid \text{나는})
- P(맛있는∣나는, 오늘)P(\text{맛있는} \mid \text{나는, 오늘})
- …
- 최종 확률 P(나는 오늘 맛있는 밥을 먹었다.)P(\text{나는 오늘 맛있는 밥을 먹었다.}) 을 계산
이 확률을 최대화하는 방향으로 모델이 학습됩니다.
② 손실 함수 (Loss Function)
학습 과정에서는 크로스 엔트로피(Cross-Entropy) 손실 함수를 사용하여 모델이 예측을 얼마나 정확하게 했는지 평가합니다.

여기서,
- : 실제 값 (Ground Truth)
- y^i : 모델이 예측한 확률값
예제)
정답이 "밥" 일 때, 모델이 "밥"일 확률을 0.8로 예측했다면,

이 값이 작을수록 모델이 정답을 잘 예측한 것입니다.
③ 미세 조정(Fine-Tuning)
사전 학습이 끝난 후, 특정 태스크(예: 문서 요약, 번역)를 수행하기 위해 미세 조정을 진행합니다.
이때, 지식 증류(Knowledge Distillation) 를 사용하여 모델을 경량화할 수도 있습니다.
미세 조정(Fine-Tuning)은 사전 학습된 모델을 특정 태스크에 맞춰 추가 학습하는 과정입니다.
예를 들어,
- 일반적인 고양이 사진을 학습한 후, 페르시안 고양이를 구별하는 모델로 튜닝
- 일반적인 언어모델을 학습한 후, 법률 문서를 요약하는 모델로 튜닝

- L CE : 원래의 크로스 엔트로피 손실
- L Distill : 작은 모델이 큰 모델의 출력을 따라가도록 유도하는 손실
- α : 가중치 조절 파라미터
④ 강화 학습 : RLHF (Reinforcement Learning from Human Feedback)
최근 ChatGPT 등에서 사용하는 방법으로, 인간의 피드백을 강화 학습으로 반영하는 방식입니다.
이 과정에서 Proximal Policy Optimization (PPO) 알고리즘을 사용하여 모델을 튜닝합니다.
예제
- ChatGPT가 "잘못된 정보"를 제공하면, 사용자가 "이 답변이 틀렸다"고 피드백
- 모델이 보상을 기반으로 더 좋은 답변을 생성하도록 학습
📌 강화 학습의 보상 함수

- r t : 특정 행동(출력)에 대한 보상값
강화 학습을 통해 모델은 더 나은 답변을 생성할 수 있도록 지속적으로 학습합니다.
모델 학습의 전체 과정 요약
- 사전 학습
- 일반적인 데이터를 학습하여 기본적인 언어 패턴을 익힘
- (예: "나는 밥을 먹었다."와 같은 일반 문장 학습)
- 미세 조정
- 특정 태스크(예: 법률 문서 요약)에 맞게 추가 학습
- 강화 학습 (RLHF)
- 사용자 피드백을 반영하여 모델을 개선
LLM의 평가 및 검증 (Evaluation & Validation)
훈련된 모델이 제대로 작동하는지 확인하기 위해 다양한 평가 지표를 사용합니다.
평가 지표는 정확성(Accuracy), 문장 유사도, 확률 모델 평가 등 다양한 방식으로 측정됩니다.
📌 평가 지표의 중요성
- 모델이 얼마나 좋은지를 판단하는 기준
- 과적합(Overfitting) 여부 확인
- 실제 서비스에서 사용자에게 적절한 결과를 제공하는지 검증
📍 1. 기본 평가 지표: 정확도 (Accuracy), 정밀도 (Precision), 재현율 (Recall), F1-score
LLM이 자연어 처리(NLP)에서 정답을 얼마나 잘 맞추는지를 평가할 때,
정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1-score 를 사용합니다.
✅ 1-1. 정확도 (Accuracy)
모든 예측 중 정답을 맞힌 비율
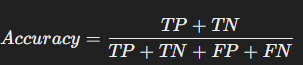
- TP (True Positive) : 실제 정답(O) → 모델이 정답(O)
- TN (True Negative) : 실제 정답(X) → 모델이 정답(X)
- FP (False Positive) : 실제 정답(X) → 모델이 정답(O)
- FN (False Negative) : 실제 정답(O) → 모델이 정답(X)
📌 예제: 고양이 사진 분류
- 모델이 100장 중 90장을 맞히면, Accuracy = 90%
- 하지만 데이터가 불균형할 경우 정확도만으로 판단하면 안됨!
문제점:
만약 데이터가 고양이 95%, 강아지 5% 라면,
모델이 "항상 고양이!"라고 예측해도 Accuracy = 95%
하지만 모델이 강아지를 구별하지 못함! 😨
👉 정확도만으로는 모델 성능을 제대로 평가할 수 없다!
✅ 1-2. 정밀도 (Precision)
모델이 정답(O)이라고 예측한 것 중에서 실제로 정답(O)인 비율

- FP (False Positive) 가 많으면 Precision이 낮음
- "고양이 사진"을 찾는 모델에서 강아지를 고양이라고 착각하면 Precision이 낮아짐
📌 예제: 스팸 필터
- 모델이 "스팸"이라고 예측한 이메일 중 실제 스팸일 확률
- Precision이 높을수록 정상 이메일을 스팸으로 잘못 분류하지 않음
✅ 1-3. 재현율 (Recall)
실제 정답(O) 중에서 모델이 정답(O)이라고 예측한 비율

- FN (False Negative) 가 많으면 Recall이 낮음
- "암 환자 예측 모델"에서 환자를 정상으로 예측하면 Recall이 낮아짐
📌 예제: 암 진단 모델
- Recall이 높을수록 암 환자를 놓치지 않음
- 하지만 Recall만 높이면 정상인도 암으로 오진할 가능성 있음 (Precision ↓)
✅ 1-4. F1-score (Precision & Recall의 조화 평균)
Precision과 Recall의 균형을 맞추기 위한 지표

- Precision과 Recall 중 하나가 너무 낮으면 F1-score도 낮아짐
- Precision ↔ Recall 트레이드오프 해결
📌 예제: 의료 진단
- 암 진단 모델은 암을 놓치면 안됨 (Recall↑)
- 하지만 너무 많은 정상인을 암으로 진단하면 안됨 (Precision↓)
- F1-score를 최적화하는 것이 중요!
📍 2. ROC 곡선과 AUC (Receiver Operating Characteristic & Area Under Curve)
✅ 2-1. ROC 곡선 (Receiver Operating Characteristic Curve)
모델의 전체 성능을 평가하는 곡선
ROC 곡선은 True Positive Rate (TPR)와 False Positive Rate (FPR) 의 관계를 나타냅니다.
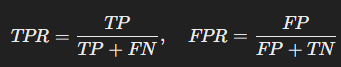
- TPR이 높고, FPR이 낮을수록 모델이 좋음
- ROC 곡선이 좌측 상단으로 올라갈수록 좋은 모델
📌 예제: 암 진단 모델
- 완벽한 모델 : (0,1) 점에 가까움
- 무작위 모델 : 대각선(랜덤 예측)
✅ 2-2. AUC (Area Under Curve)
ROC 곡선 아래 면적

- AUC = 1 : 완벽한 모델
- AUC = 0.5 : 랜덤 예측 모델
- AUC < 0.5 : 모델이 오히려 잘못된 예측을 함
📌 예제: 스팸 필터
- AUC가 높을수록 스팸을 잘 탐지하는 모델
📍 3. 자연어 처리(NLP) 모델의 평가 지표
LLM의 성능을 평가할 때, NLP에 특화된 지표도 사용합니다.
✅ 3-1. BLEU (Bilingual Evaluation Understudy)
기계 번역 성능을 평가하는 지표

- BLEU가 높을수록 번역 품질이 좋음
- 인간 번역과 얼마나 유사한지 평가
📌 예제: 기계 번역 (English → 한국어)
정답: "나는 오늘 맛있는 밥을 먹었다."
번역 결과 1: "나는 오늘 맛있는 밥을 먹었습니다." (BLEU ↑)
번역 결과 2: "나는 밥을 먹었다." (BLEU ↓)
✅ 3-2. ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
문서 요약 성능 평가 지표
ROUGE는 정답과 얼마나 유사한지 비교하는 방식입니다.
- ROUGE-N : 단어 개수 기준 비교
- ROUGE-L : 문장 구조를 고려한 비교
📌 예제: 뉴스 요약
정답: "미국 대선에서 바이든이 승리했다."
요약 결과 1: "바이든이 미국 대선에서 승리했다." (ROUGE ↑)
요약 결과 2: "트럼프가 대선에 나왔다." (ROUGE ↓)
✅ 3-3. Perplexity (혼란도)
언어 모델이 얼마나 "놀라는지" 평가하는 지표

- Perplexity가 낮을수록 좋은 모델
- 낮으면 낮을수록 모델이 문장을 더 잘 예측
📌 예제: 텍스트 생성 모델
- "나는 오늘 맛있는 밥을 ..." → "먹었다" (Perplexity ↓)
- "나는 오늘 맛있는 밥을 ..." → "비행기" (Perplexity ↑)
📍 결론
모델의 성능을 평가할 때는 여러 지표를 함께 고려해야 합니다.
- Classification 문제: Precision, Recall, F1-score, ROC-AUC
- NLP 문제: BLEU, ROUGE, Perplexity
📌 LLM의 배포 및 유지보수: AI 모델의 지속적 발전을 위한 핵심 과정
LLM(Large Language Model)은 단순히 학습 후 배포로 끝나는 것이 아닙니다. 배포 이후에도 지속적인 유지보수와 최적화가 필수적이며, 이 과정에서 다양한 기술적 요소와 관리 기법이 활용됩니다. 이를 자세히 분석해 보겠습니다.
🔹 1. 모델 배포의 개념
모델 배포(Deployment)란, 개발된 LLM을 실제 환경에서 사용자들이 활용할 수 있도록 배포하는 과정입니다. 일반적으로 온프레미스(On-Premise) 배포와 클라우드 배포(Cloud Deployment) 방식이 존재합니다.
📌 온프레미스(On-Premise) 배포
- 기업 내부 서버에서 모델을 직접 운영
- 보안과 데이터 프라이버시 강화
- 초기 인프라 구축 비용이 높음
- 예시: 금융, 의료 등 민감한 데이터를 다루는 기업의 AI 모델 배포
📌 클라우드 배포(Cloud Deployment)
- AWS, GCP, Azure 등의 클라우드 플랫폼을 활용하여 배포
- 서버리스(Serverless) 또는 컨테이너(Container) 기반 배포 가능
- 확장성(Scalability) 및 유지보수 용이
- 예시: OpenAI의 GPT API, Google Bard, Claude
🔹 2. 배포 방식의 종류와 전략
📌 ① 실시간 배포 (Real-Time Deployment)
- API 형태로 제공하여 실시간으로 사용자 요청에 응답
- OpenAI의 GPT API처럼 REST API를 통해 제공 가능
- 사용 사례: 챗봇, 음성 비서, 실시간 번역기
📌 ② 배치 배포 (Batch Deployment)
- 일정한 시간 간격으로 데이터를 처리하여 결과를 반환
- 예를 들어, 하루 한 번 새로운 데이터로 문서 요약을 수행
- 사용 사례: 뉴스 요약, 대량 문서 번역
📌 ③ 엣지 배포 (Edge Deployment)
- 모델을 클라우드가 아닌 개별 장치(모바일, IoT 디바이스 등)에서 실행
- 네트워크가 불안정한 환경에서도 동작 가능
- 사용 사례: 스마트폰 음성 비서, AI 카메라
🔹 3. 모델 배포 후 유지보수 (Maintenance)
배포된 LLM이 실무에서 지속적으로 좋은 성능을 유지하려면 정기적인 유지보수가 필요합니다.
📌 ① 사용자 피드백 기반 모델 업데이트
LLM이 배포된 후에는 사용자들이 실제로 어떻게 활용하는지 모니터링하고, 피드백을 반영하여 모델을 개선해야 합니다.
- 사용자 로그 분석: 유저들이 어떤 질문을 많이 하는지, 오류가 발생하는 패턴 분석
- 모델 업데이트 주기 설정: 주기적으로 Fine-Tuning 또는 RLHF(Reinforcement Learning from Human Feedback) 적용
- 모델 개선 방식:
- 데이터 추가 학습 (Incremental Learning)
- 새로운 태스크를 학습하는 Transfer Learning
📌 ② 지속적인 데이터 재학습 (Continuous Learning)
배포된 모델은 시간이 지남에 따라 최신 데이터와 트렌드를 반영해야 합니다.
✅ 데이터 재학습 방법
- Online Learning: 실시간으로 새로운 데이터를 학습하여 모델을 업데이트
- Offline Learning: 일정 주기마다 새로운 데이터를 수집하여 다시 학습 후 배포
- Transfer Learning: 기존 모델을 기반으로 새로운 데이터셋을 학습하여 특정 도메인에 최적화
✅ 예제: 뉴스 요약 AI 모델의 데이터 업데이트
- 초기에는 2022년까지의 뉴스 데이터로 학습된 모델을 배포
- 2023년 이후 새로운 뉴스가 등장 → 최신 뉴스 반영 필요
- 새로운 데이터를 수집하여 Fine-Tuning 진행
- 모델 성능 평가 후 새로운 버전 배포
📌 ③ 모델 성능 평가 및 재조정 (Evaluation & Tuning)
LLM이 지속적으로 좋은 성능을 내기 위해서는 성능 평가가 필수적입니다.
✅ 주요 평가 지표 (Evaluation Metrics)
| Perplexity (혼란도) | 언어 모델이 얼마나 정확하게 예측하는지 측정 (값이 낮을수록 좋음) |
| BLEU (Bilingual Evaluation Understudy) | 기계 번역의 정확도를 평가하는 지표 |
| ROUGE (Recall-Oriented Understudy for Gisting Evaluation) | 텍스트 요약 모델의 성능을 평가하는 지표 |
| F1 Score | 정밀도(Precision)와 재현율(Recall)의 조화 평균 |
| AUC-ROC (Area Under Curve - Receiver Operating Characteristic) | 이진 분류 모델의 성능을 측정 |
✅ 예제: Perplexity 계산 방법
Perplexity는 모델이 예측한 확률의 역수를 평균적으로 계산한 값입니다.
수식:

예제 문장: "나는 오늘 맛있는 밥을 먹었다."
각 단어의 예측 확률이 다음과 같다면:
- P(나는) = 0.1
- P(오늘) = 0.05
- P(맛있는) = 0.2
- P(밥을) = 0.15
- P(먹었다) = 0.5

해당 값이 낮을수록 모델이 문장을 잘 예측하고 있다는 의미입니다.
📌 ④ 모델 경량화 및 최적화
배포된 모델이 너무 크면 연산 속도가 느려지고 운영 비용이 증가할 수 있습니다. 이를 해결하기 위해 모델 경량화(Model Compression) 기술을 활용합니다.
✅ 모델 경량화 기법
| 지식 증류 (Knowledge Distillation) | 큰 모델(Teacher Model)의 지식을 작은 모델(Student Model)로 전이 |
| 양자화 (Quantization) | 모델의 파라미터를 32-bit에서 8-bit 등으로 줄여 계산량 감소 |
| 프루닝 (Pruning) | 모델의 불필요한 뉴런을 제거하여 경량화 |
✅ 예제: GPT 경량화
- GPT-3(175B) → 너무 크기 때문에 API 비용이 비쌈
- DistilGPT-3(66B)로 지식 증류를 적용하여 더 가볍게 운영
🔹 4. 모델 유지보수 자동화 (MLOps)
LLM의 지속적인 유지보수를 위해 MLOps(Machine Learning Operations) 자동화 프로세스를 구축할 수 있습니다.
✅ MLOps 주요 단계
- 데이터 수집 자동화 (크롤링, ETL 파이프라인)
- 모델 학습 자동화 (자동 재학습, CI/CD)
- 성능 평가 및 모니터링 (실시간 로그 분석, A/B 테스트)
- 배포 및 롤백 (새 모델 배포 후 성능 저하 시 롤백)
예제: Google의 TFX (TensorFlow Extended)
- Google은 TFX를 활용하여 Gmail의 자동완성 AI를 지속적으로 업데이트
🔹 결론
LLM의 배포 및 유지보수는 단순한 모델 배포가 아니라 지속적인 개선과 최적화가 핵심입니다.
1️⃣ 배포 방식 선택 (API, Batch, Edge AI)
2️⃣ 사용자 피드백 반영 (Fine-Tuning, RLHF)
3️⃣ 모델 평가 및 성능 개선 (Perplexity, BLEU, ROUGE)
4️⃣ 경량화 및 자동화 적용 (Knowledge Distillation, MLOps)
'인공지능 > 랭체인' 카테고리의 다른 글
| 4. Retrieval-Augmented Generation (RAG): 대규모 언어 모델(LLM)과 정보 검색의 결합 (0) | 2025.04.02 |
|---|---|
| (궁금) 시맨틱 검색(Semantic Search)와 코사인 유사도(Cosine Similarity)이란 뭘까? (0) | 2025.04.02 |
| (궁금) BM25 (Best Matching 25) 이란 무엇일까? (0) | 2025.04.01 |
| (궁금) TF-IDF (Term Frequency-Inverse Document Frequency)가 뭘까 (0) | 2025.04.01 |
| 3. LLM의 활용과 학습 과정: 이론적 접근과 응용 (0) | 2025.04.01 |




댓글