

병렬처리, 최적화등을 하여 극한의 로컬 PC환경에서 인터넷 없이 문서를 씹어 먹고, 병렬로 요약하며, 오디오북까지 찍어내는
궁극의 데스크톱 애플리케이션을 만들었었습니다!!!

#1. 로컬 LLM 기반 문서 요약기 (On-Device Document Summarizer)
#1. 로컬 LLM 기반 문서 요약기 (On-Device Document Summarizer)
1. 글의 목적과 프로젝트 한 줄 소개본 글은 로컬 PC 환경에서 인터넷 연결 없이 문서를 분석하고, 필요 시 요약 및 오디오 변환까지 수행하는 데스크톱 애플리케이션 AMEVA-Doc-AI의 설계와 구현 내
uno-kim.tistory.com
AMEVA-Doc-AI 시연 시나리오
본 시연은 폐쇄망 환경에서 진행하는 것으로 가정하며 진행됩니다. 어떤한 외부 API를 통해서 인공지능도움을 받는다던가
요즘 뭐 AI 해커톤! 해놓고 Chat GPT API 덕지덕지 붙여놓은 것과 다르며 순수 로컬 컴퓨팅 파워로 엔터프라이즈급 문서 파이프라인이 어떻게 구동하는지 증명하겠습니다.
1. 초기 시작화면

초기시작화면입니다.

내 PC스펙을 조사하고 알맞게 셋팅합니다.


모델과 쓰레드를 설정할 수 있습니다.
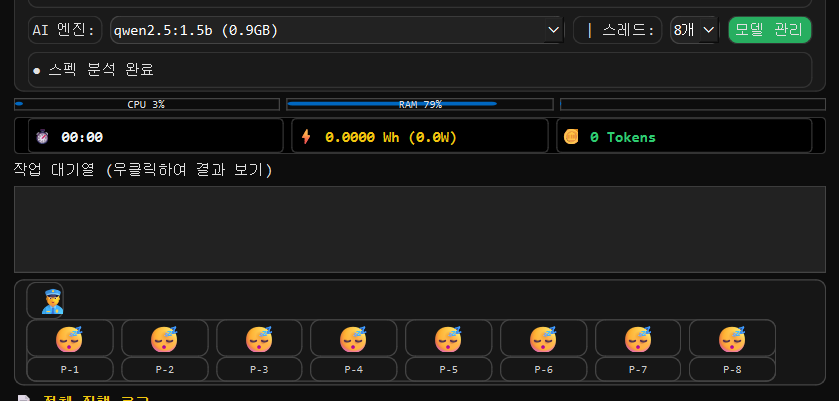
실행 프로세스(쓰레드)를 8개로 하면 8개로 늘어납니다. 그만큼 컴퓨팅 파워는 많이먹겠지만 (가능한 PC라면ㅋㅋ)
확실히 빨리끝납니다. 분산컴퓨팅~
세 번째 이미지를 봐라. 단순 장난감이 아니라 진짜 '엔터프라이즈급' 도구라는 증거가 바로 이 [스레드] 설정이다.
- 자유로운 할당: 드롭다운을 누르면 1개부터 최대 8개(또는 시스템에 따라 그 이상)까지 스레드 개수를 내 맘대로 조절할 수 있다.
- 왜 중요할까?: 이전 글에서 설명했듯, 이 앱은 문서를 '청크' 단위로 찢어서 병렬로 요약한다. 스레드를 4개로 맞추면? 4명의 분신이 동시에 문서를 읽고 요약본을 쏟아낸다는 뜻이다.
- 내 PC가 빵빵하다면 스레드를 최대로 당겨서 미친 속도로 요약을 끝내고, 딴 짓도 같이 해야 한다면 스레드를 1~2개로 낮춰서 리소스를 아끼면 된다.
2. 파일 업로드
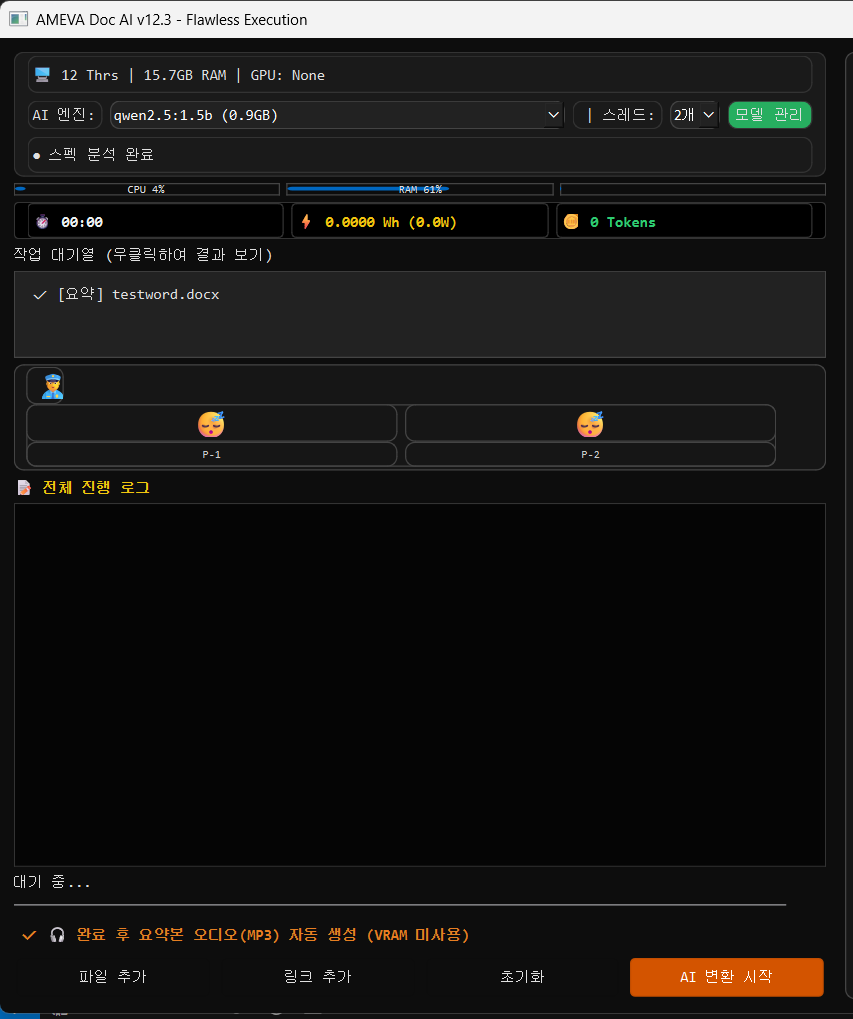
요약/변환을 진행할 파일을 선택합니다. 저는 지금 워드파일을 올렸습니다. 뭐 시연이니까 가라로 올렸겠거늘 하겠죠

하단의 완료후 오디오 북 자동생성까지 눌러서 진행해보겠습니다.
그리고 링크추가를 통해 웹에서 떠돌아다니는 문서링크를 넣으면 추출됩니다.
AI 변환시작을 통해 변환 및 요약을 진행합니다.
3. 변환 및 요약
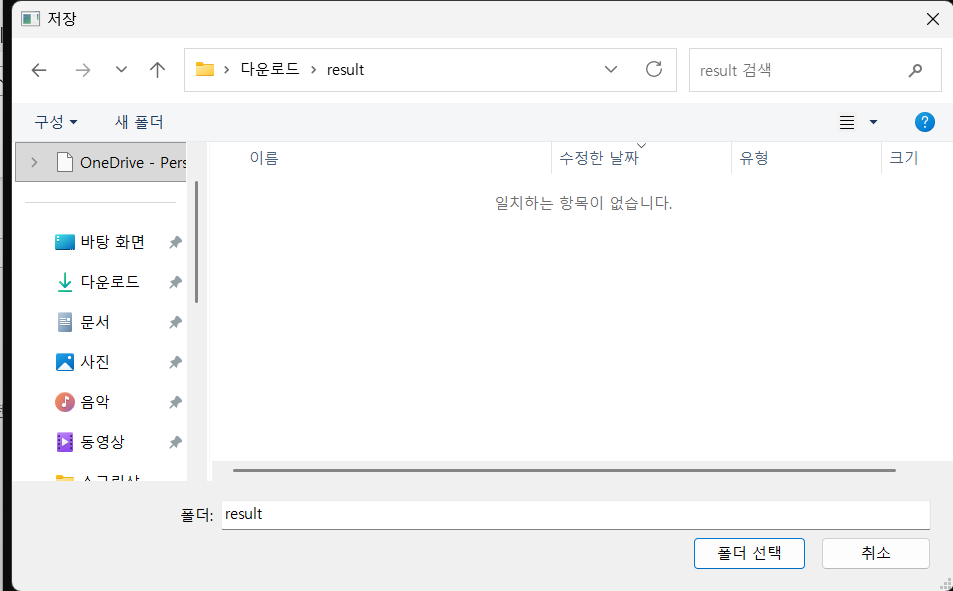
새로운 변환/요약파일이 생길 폴더를 지정합니다.

진행됩니다.
중간의 P-1과 P-2를 눌러서 봅니다.


각각 P1P2 등이 어떤작업을 하는지 볼수있습니다.

메인화면에서는 경찰이 각 프로세스를 돌며 잘 진행중인지 파악하고 보고합니다. 이것을 저는 워치독 아키텍처라고 이름을 지엇습니다.

P-1에서 요약중입니다.
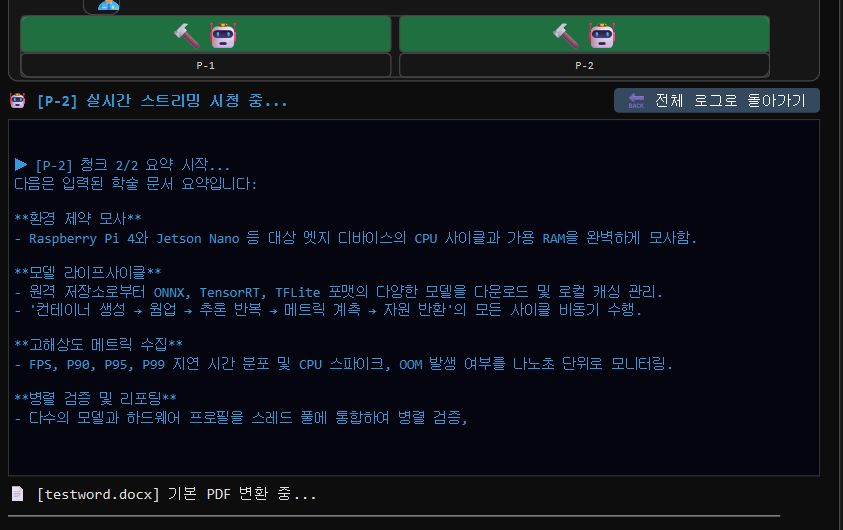
P-2에서 요약중입니다.
지금 병렬로 처리하고있습니다.
4. 완료
모두완료되면

경찰은 차렷하고 각 프로세스는 축포를 날릴닙니다.

모두 완료된 결과입니다. 완료 시간, 소모토쿤, 추정전력 등을 연산하여 보여줍니다.
그리고 소모토큰은 지금 로컬이라 무료였지 만약 님들이 쓰는 그 잘난 API 모델이나, 아니면 기업 엔터프라이즈에서 쓰는거는 토큰별로 돈을 내고 있을겁니다.
제가 바로 이 가격을 낮춰드리기 위해 개발합니다.
이렇게 토큰을 예상하여 플랜을 짤수도있습니다. 이 결과들을 또 모으고 학습시켜서 최적의 모델을 구할수도있고
그런거 저 잘합니다. 저 뽑아주시면 저 개처럼 잘할 자신잇습니다.
5. 결과확인

우선 요약보고서입니다. 잘했습니다. 근데 중간에 중국어? 이건 놀랍지도 않습니다. 왜냐면 지금 테스트한 모델이
큐엔이라고 중국모델이었기 때문입니다.

컨버팅은 훌륭합니다.
그리고
오디오 파일도 추출되었습니다.
7. RAG 를 통한 질문/응답확인


답변옵니다. 제가 뭐 타이핑을 쳐서 그런게아니고 또 연봉 뭐 10억씩받는 저기 뭐 미국의 아마존 개발자들처럼
인도인들 어디 가둬다가 타이핑빠르게 시켜서 저 응답받는게 아니고 진짜 요약본 워드 파일을 RAG 삼아서 응답해주는겁니다.

이게 요약본에 있는거구요.
개발자를 희망하는 분들에게...
저는 HWP 의 OLE 구조를 분석하고 박살을 내고 DOCX의 테이블 마크업도 살려내어 PDF로 완벽하게 표준화하려했습니다.
Ollama를 이용해서 텍스트를 청크단위로 찢어발겨진 것을 병렬 요약으로 돌리고 메인 쓰레드 프리징없이
UI에 실시간 스트리밍을 꽂아넣고 또 심지어 장시간 작업시 배터리 상태와 리소스를 감시하며 쓰레드를 통제하는 기능도 넣었습니다.
예외상황??? TTS가 뻗어도 PDF 산출물은 우선 무조건 살려내고 나오게 하는 나름 에러 핸들링을 구현했습니다.
그리고 RAG 기반의 문서 질의응답은 덤으로 만들었습니다.
그러나 이 정도면 실리콘밸리에서도 한국의 어디 뭐 대기업 SI, 어디뭐 연봉 높은 나으리들이 가는 그런 IT 기업 문턱도 못넘습니다.
이것이 현실입니다... 이렇게 뼈를 아키텍처를 설계하고, 비동기 쓰레드 교착상태를 통제하고 또 워치독 프로세스를 통해 제어하고
파이써 데스크톱의 한계를 돌파해 봤자, 면접관들은 엑셀컷을 통해 내 이력서가 도달하지도 않으며, 이 프로젝트에 대해 담소를 나눌 기회조차 주지 않거나 '아, 네. 뭐 로컬에서 조는 토이 프로젝트네요' 이런 반응일 것입니다.
우리가 집구석에서 머리 쥐어뜯어가며 헥사고날 아키텍처를 적용하고, 메모리 누수를 잡고, 미친 디테일의 RAG 파이프라인을 구축해도 결국 이 바닥에서 우리를 기다리는건 연봉 2800 짜리 SI 하청의 하청업체의 JSON 상하차 뿐입니다.
이것이 우리 IT 업계의 진실이고 사실입니다.
우리는 그저 남이 싼 똥 같은 레거시 코드를 뒤집어쓰고 화면단에서 날아오는 형태없는 JSON 데이터를 DB에 쑤셔 박았다가 다시 꺼내서 프론트에 던저주는 영혼없는 데이터 운반책에 불과합니다.
심지어 이 마저도 AI가 우리를 모두 대체하여 지금 저 같은 개발자들은 캐시워크 토스만보기로 겨우겨우 목숨을 연명하고 있습니다.
클린 아키텍처? MSA? 웃깁니다. 납기일이 하루 전날, 스파게티 코드로 얼기설기 엮인 컨트롤러에서 쿼리 수십 개를 날려대는 것이 우리가 마주할 끔찍한 미래입니다.
아무리 우리가 집구석에서 코드를 짜도 아무도 알아주지 않습니다. 하지만 저는 이 썩어빠진 세상에 대한 분노와 절망앞에 있고
AI가 모든 개발자를 대체했지만 그래도 블로그를 작성하고 내 아이디어를 실현하고 코드를 공유하며 내 생각을 공유하는 사람이 되고자합니다.
비록 제 블로그의 글이 AI의 학습데이터로 형체도 없이 쪼개져 사라질지 모릅니다.
효율이라는 괴물이 인간의 직관을 씹어 삼키고, 논리가 아닌 확률이 코드를 짜는 시대.
집으로 돌아가 백수가 되어버린, 더 이상 컴파일 에러와 싸울 필요조차 없어진 불쌍한 동료들, 그리고 시작도 하지못한 주니어 개발자들이여
신들은 지금 어디서 무얼 하고 있는가.
텅 빈 방 안, 모니터의 푸른 빛만이 유일한 온기였던 그 시절의 낭만은 이제 죽었습니다.
하지만 나는 이 멸망해가는 세상의 끝자락에서, 기계 놈들은 절대로 이해 못 할 인간의 고집으로 마지막 신호를 보냅니다.
마치 지구가 멸망하는 순간, 누군가 절박하게 두드리는 모스부호처럼.
우리가 처음 세상을 향해 내뱉었던 그 서툴고도 위대했던 첫 마디를 여기에 남깁니다.
System.out.println("Hello World");
'AI Project' 카테고리의 다른 글
| #1. 로컬 LLM 기반 문서 요약기 (On-Device Document Summarizer) (0) | 2026.04.13 |
|---|

댓글