
안녕하세요 요즘 하는 일이 너무 바빠서
티스토리 블로그업로드가 많이 미뤄졌었네요 ㅠㅠ
진행전에 앞서서 라이브러리 설치나 사용방법을 참고하시고 진행해주시면 더욱 부드럽게 진행 될 수 있겠습니다.!!!ㅎㅎ

Jsoup 설치 방법 (자세히)
https://uno-kim.tistory.com/213
[JAVA]Jsoup 라이브러리를 이용한 크롤링 - Jsoup 사용법 + 라이브러리 저장하는 법
안녕하세요~! ㅎㅎ 오늘 포스팅은 그동안 크롤링를 하여 네이버 금융의 정보를 가져왔었는데 크게 사용되었던 라이브러리인 Jsoup 라이브러리 사용법 에 대해서 알아보겠습니다! 1. 라이브러리
uno-kim.tistory.com
Jsoup 사용방법(3가지 방법 소개)
https://uno-kim.tistory.com/215
[JAVA]Jsoup 라이브러리를 이용한 크롤링 - Jsoup 사용법
안녕하세요! 오늘 포스팅은 Jsoup 라이브러리를 알아보려고 해요 해당 라이브러리는 가장 편한 API 를 제공하며 HTML5 DOM 메서드와 CSS 선택기를 사용하여, URL을 가져오고 데이터를 추출 및 조작하기
uno-kim.tistory.com
저번 글로는 코스피, 코스닥을 가져오는 방법에 대해 진행했습니다.
https://uno-kim.tistory.com/206
네이버 금융페이지를 몽땅 가져와보자! - 코스피, 코스닥을 긁어오자!
안녕하세요!~ 오랜만입니다. ㅎㅎㅎ 저번 포스팅은 값들을 가져오는 환경과 데이터만 가져오는 방법으로만 구현했네요 이제 크롤링을 간단하게 해서 직접 자바의 자료구조 형태로 저장을 해보
uno-kim.tistory.com
이번엔 기타 정보들
주요뉴스, 시가총액 상위, 차트이미지, 매매동향, 일일변동, 금-환율-원자재-유가 등 상품 등등
총 6가지의 정보를 가져 올 수 있는 키워드를 알아 보겠습니다.
첫 번째로 주요뉴스 정보를 가져올 수 있는 키워드 입니다!

사진을 보시면 아시겠지만 주요 뉴스의 소스는
크게 div 태그의 news_area안의 section_strategy 클래스에 있습니다. 이것을 HTML 요소에서 본다면

이렇게 new_area 하위의 클래스에 있습니다.
저의 경우는 한 계층을 더 내려서 검색하기 위해 section_strategy를 사용하겠습니다.
자바소스는 아래와 같습니다.
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class CrawlingNaverFins
{
public static void main(String[] args) throws IOException
{
/* url 셋팅하고 파서셋팅하고, doc 셋팅하는 부분 */
final String URL = "https://finance.naver.com/"; // <-- 가져올 url
final String pharser = ".section_strategy";
Document doc = Jsoup.connect(URL).get(); // <-- 해당부분에서 doc에 url의 HTML 문서가 모두 들어가게 된다.
/* 셋팅 부분 끝 */
/* 구분자를 통해 데이터들을 잘게 쪼갠다. */
Elements header = doc.select(pharser);
System.out.println(header);
}
}그리고 하단의 사진은 결과입니다.

보시는 바와 같이 <div>태그 클래스명은 섹션 스트래티지 라는 이름으로 있는 엘리먼티에
하위로 <ul> 태그가 있으며, 그곳에 또 <li> 태그로 우리가 원하는 값들이 있음을 발견 할 수 있습니다.
따라서 Jsoup라이브러리의 돔파서와 같은 같은 기능을 이용해서 우리가 찾고자하는 데이터만 추출받아봅시다
우선은 해당 태그 내에 순수 텍스트 부분만 가져와야하므로
.get(i).text() 함수를 이용해서 텍스트 부분을 가져옵니다.
.여기서 부연설명으로는
우리는 <li> 태그내의 <a>가 복수개인것을 알 수 있습니다.
이것을 자료형으로 보면 List<String> 형태로 나오게 됨을 알 수있습니다.
따라서 인덱스 i를 통해서 얻어오자면
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class CrawlingNaverFins
{
public static void main(String[] args) throws IOException
{
/* url 셋팅하고 파서셋팅하고, doc 셋팅하는 부분 */
final String URL = "https://finance.naver.com/"; // <-- 가져올 url
final String pharser = ".section_strategy";
Document doc = Jsoup.connect(URL).get(); // <-- 해당부분에서 doc에 url의 HTML 문서가 모두 들어가게 된다.
/* 셋팅 부분 끝 */
/* 구분자를 통해 데이터들을 잘게 쪼갠다. */
Elements header = doc.select(pharser).select("a");
for (int i = 0; i < header.size(); i++)
{
System.out.println(header.get(i).text());
}
}
}해당 소스를 이용한 결과는

위와 같이 뉴스제목만 가져올 수 있다.
두번째 : 시가총액 상위 가져오기
이번에는 조금 간단하다
우선 사진이나 설명은 생략하겠지만 시가총액 상위 가져오는 키워드는
#_topItems4 입니다.
왜냐하면 해당 섹션은 클래스로 가져오는것이 아니고 아이디로 가져왔기 때문에 #을 붙입니다.
자바소스
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class CrawlingNaverFins
{
public static void main(String[] args) throws IOException
{
/* url 셋팅하고 파서셋팅하고, doc 셋팅하는 부분 */
final String URL = "https://finance.naver.com/"; // <-- 가져올 url
final String pharser = "#_topItems4";
Document doc = Jsoup.connect(URL).get(); // <-- 해당부분에서 doc에 url의 HTML 문서가 모두 들어가게 된다.
/* 셋팅 부분 끝 */
/* 구분자를 통해 데이터들을 잘게 쪼갠다. */
Elements header = doc.select(pharser);
System.out.println(header);
}
}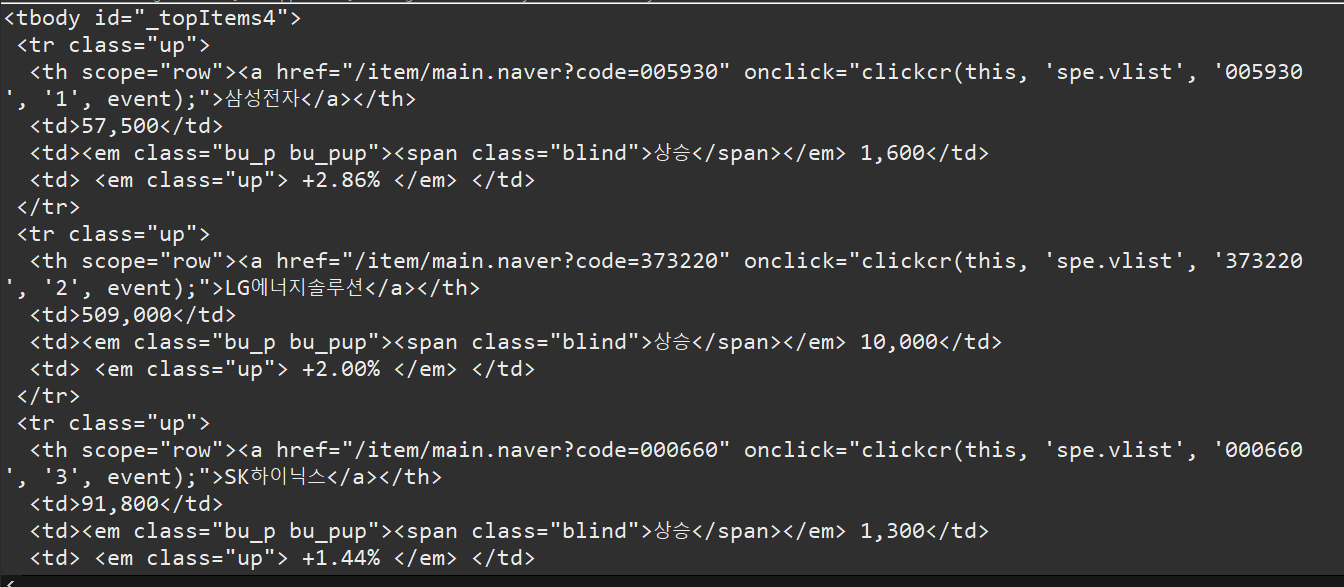
결과는 조금 복잡해 보이시겠지만 위와같이 나옵니다. 하지만 결코 복잡하지 않습니다.
이또한 특정한 패턴으로 나누어져있고 잘 나누어준다면 간단합니다.
이것은 표 형태 (tbody)형식으로
tr로 구분하여 출력해보겠습니다.
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class CrawlingNaverFins
{
public static void main(String[] args) throws IOException
{
/* url 셋팅하고 파서셋팅하고, doc 셋팅하는 부분 */
final String URL = "https://finance.naver.com/"; // <-- 가져올 url
final String pharser = "#_topItems4";
Document doc = Jsoup.connect(URL).get(); // <-- 해당부분에서 doc에 url의 HTML 문서가 모두 들어가게 된다.
/* 셋팅 부분 끝 */
/* 구분자를 통해 데이터들을 잘게 쪼갠다. */
Elements header = doc.select(pharser).select("tr");
for (int i = 0; i < header.size(); i++)
{
System.out.println(header.get(i).text());
}
}
}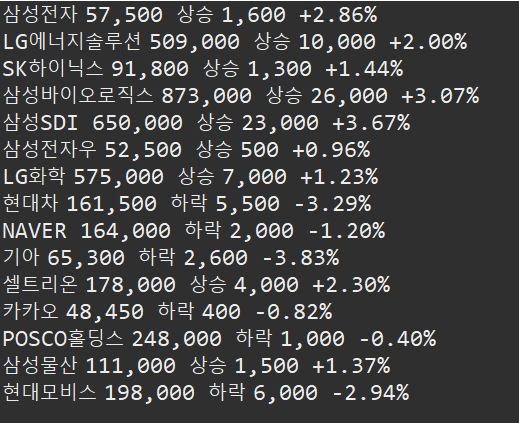
이렇게 아래와 같이 상위종목들의 종목을 가져 올 수 있습니다.
세번째 : 매매동향 가져오기
매매동향 키워드는 : .dd 이나
여기서 주의해야할 점은 우리가 지금까지 사용하던
네이버 금융 홈페이지에서 가져올수가 없다!

??? : 흠... 그럼 어떻게 가져올까요?
그러나 방법이 있습니다.
해당 매매동향키워드는 시장구분에 따라 상세 페이지로 들어가면 고정된 값으로 가져올 수 있습니다.
말을 좀 어렵게 하였으나,
즉 우리는 `https://finance.naver.com/` 와 같은 URL에서
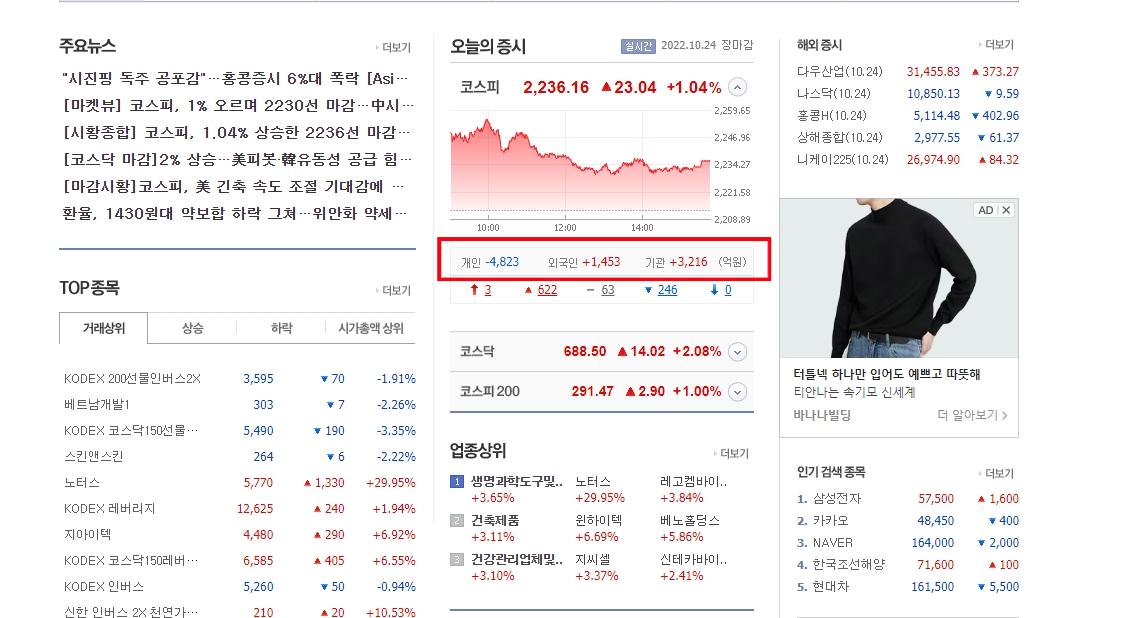
빨간 사각형을 보시는 바와 같이 메인에서 보이더라도 가져올 수 없지만
https://finance.naver.com/sise/sise_index.naver?code=KOSPI 와 같이
코스피의 세부화면으로 이동하면

위와같은 정보를 가져올 수 있습니다.
따라서 자바코드의 URL 부분을 수정해 주어야합니다.
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class CrawlingNaverFins
{
public static void main(String[] args) throws IOException
{
/* url 셋팅하고 파서셋팅하고, doc 셋팅하는 부분 */
/* 매매 동향의 경우 URL을 수정해야한다. */
final String URL = "https://finance.naver.com/sise/sise_index.naver?code=KOSPI"; // <-- 가져올 url
final String pharser = ".dd";
Document doc = Jsoup.connect(URL).get(); // <-- 해당부분에서 doc에 url의 HTML 문서가 모두 들어가게 된다.
/* 셋팅 부분 끝 */
/* 구분자를 통해 데이터들을 잘게 쪼갠다. */
Elements header = doc.select(pharser);
System.out.println(header);
}
}URL 부분을 수정했습니다. 그리고 키워드는 .dd 로 설정했습니다.
결과는
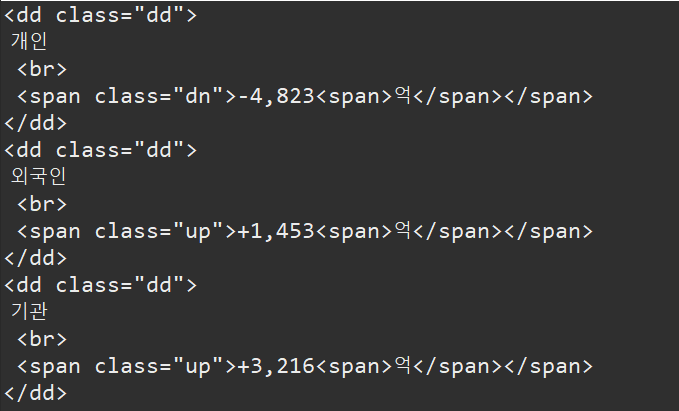
그래서 깔끔하게 값만 가져오고 싶다면
package ㅎJavaTests;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class CrawlingNaverFins
{
public static void main(String[] args) throws IOException
{
/* url 셋팅하고 파서셋팅하고, doc 셋팅하는 부분 */
/* 매매 동향의 경우 URL을 수정해야한다. */
final String URL = "https://finance.naver.com/sise/sise_index.naver?code=KOSPI"; // <-- 가져올 url
final String pharser = ".dd";
Document doc = Jsoup.connect(URL).get(); // <-- 해당부분에서 doc에 url의 HTML 문서가 모두 들어가게 된다.
/* 셋팅 부분 끝 */
/* 구분자를 통해 데이터들을 잘게 쪼갠다. */
Elements header = doc.select(pharser);
for (int i = 0; i < header.size(); i++)
{
System.out.println(header.get(i).text());
}
}
}
이렇게 하루 매매동향, 그리고 프로그맹 매매동향을 가져올 수 있습니다.
지금까지
네이버 금융 뉴스 크롤링
네이버 금융 시가총액 순위 크롤링
네이버 금융 매매동향 크롤링
이렇게 오늘은 총 3가지 정보를 가져오는 키워드를 알아 보았습니다.
다음 포스팅은 나머지
이미지, 기타상품, 그리고 대망의 각 종목의 세부정보모두 가져오기
등을 포스팅하겠습니다.
개인적으로 프로젝트 준비하시는 분들에게 어느정도 관심이 있으실텐데 혹시 모르는게 있다면
댓글로 질문해주세요 감사합니다.
'프로젝트 > 금융' 카테고리의 다른 글
| 네이버 금융 크롤링 : 주식 종목 가져오기 (4) | 2022.10.26 |
|---|---|
| 네이버 금융 크롤링 : 환율 금리 유가 차트 이미지를 가져와 보자! (0) | 2022.10.25 |
| 네이버 금융페이지를 몽땅 가져와보자! - 코스피, 코스닥을 긁어오자! (0) | 2022.05.03 |
| 네이버 금융페이지를 몽땅 가져와보자! - 자바 크롤링(java)_2 , 종목코드와 종목명 매핑하기 (0) | 2022.03.24 |
| 네이버 금융페이지를 몽땅 가져와보자! - 자바 크롤링(java)_1 (0) | 2022.03.17 |




댓글